Markets That Explain Themselves
We introduce evidence markets, a mechanism generalizing prediction markets by paying for both accurate forecasts AND the evidence that explains them. Evidence markets also generalize resolution by allowing the evidence gathered within a markets lifecycle to settle the market itself.

Prediction markets are pitched as forecasting and decision-making infrastructure. However, in practice, most of the money is on sports. Through early 2026, sports made up roughly 80% of trading volume on Kalshi and 39% on Polymarket.
The usual explanation is a story about traders — a crowd showed up to wager on games, not to deliberate over anything that matters. We believe that narrative gets the causality backwards, and that the story lets the platforms and their market designers off the hook. Markets attract what they pay for. A venue that pays you to take a position on an externally-resolved event, hands back nothing but a price, and runs on an order book that rewards speed and inventory will be populated by the people that setup rewards: bettors, arbitrageurs, and market-makers. The gambling isn't the mechanism failing. It's the mechanism selecting.
We’ll start with what the machinery does well, because it really is remarkable. A prediction market takes a question with an uncertain answer, asks people to back their beliefs with money, and folds thousands of private judgments into a single number that updates in real time. Having to put money on a claim sharpens it, and the prices that come out have a track record of beating polls and expert panels. That core — incentives that reward being right, compressed into a live estimate — is worth keeping, and so we'll do precisely that.
Unfortunately, a compression that aggressive will strip away almost everything that produced it. In particular, two of the things it discards are the two you most want when stakes are real:
The first is the reasoning. A price reports what the crowd concluded, not why they concluded it. The rationale behind each individual’s judgement — their private evidence, the argument that changed their mind, their mental model, etc. — do not survive into the number. You get the verdict and none of the testimony. For anyone who has to act on a forecast rather than just betting alongside it, that missing testimony is most of what they came for. Concretely, consider an institutional perspective, it is difficult to trade/hedge on future events when the catalysts for those beliefs are unknown. If one compares prediction market forecasting to classic buy/sell side analysts in equity or commodity markets, the latter provides rationales and justifications for their beliefs; even if the underlying belief is worse than prediction markets, the rationale serves a crucial role in aligning the internal perspectives of traders with the forecaster.
The second is more fundamental, because it decides which questions a market can take at all. Standard prediction markets need resolution terms tethered to answers the world will produce by a known date. Elections get called, games end, prices print. That certainly covers a lot, but it leaves out an enormous class of questions whose answers come from judgment and evidence rather than the passage of time. Did the policy do what it promised? Will the result replicate? Which of two tools is the better fit for the job in front of you? Nature will never ring a bell and settle these on its own; the answer has to be assembled, not observed.
Put the two together and the complaint changes character. Three design choices, although each is reasonable on its own, compound here. Bet-shaped questions admit only what nature will settle on a clock, which subtly blunts the questions where domain experts have an inherent edge. A price-only output discards the reasoning, which leaves a person who has to act on the forecast with a hollow artifact: a number and no testimony. Finally, an order book pays for liquidity, latency, and inventory, which rewards the people who make markets over the people who use them — you can see this phenomenon in the fact that much of the serious capital that arrives in popular markets today are coming to make markets, not to act on them. None of this is a marketing problem, and it is unlikely to be a coincidence. It is what the mechanism selects for. If you want the people who need to understand a situation before they act on it, better questions alone will not coax them in; you have to change what the market pays for and what it is allowed to resolve.
That is what we do in our recent paper, which introduces a mechanism we call evidence markets. We keep the potent parts of prediction markets — incentives behind being right, information aggregation into prices — and add a second set of incentives behind the underlying reasons; we pay people not only to be correct, but to show why, and to bring the evidence that can settle the questions a calendar never will. The output is no longer a bare price. It is closer to an analyst's report — one produced in public, by the crowd, and priced as it is built.
A canonical example that highlights both failures happening at once is increasingly ubiquitous: which AI model is “best”.
Static solutions won't catch moving targets
AI is progressing at a dizzying rate; new models seemingly land weekly, and each one comes trailing a fresh row of benchmark scores. Those numbers, despite being near-universally viewed as flawed, were a decent guide for a while. However, they're aging poorly.
The problem from the last section rears its head here in concentrated form — both failures at once, in disguise. "Which model is better?" is a comparison no event will ever settle; there is no election night for model quality, nor a date on which the world announces a winner. Furthermore, even supposing a leaderboard hands you a ranking, it hands you a number, not the thing you realistically need when choosing a model to use on a task — which prompts expose the gap, where the weaker model quietly goes wrong, what its failures look like on the work you actually do. The what without the why, for a question with no resolution date.
The standard response is to build a better benchmark. We think that's the wrong move, and not by a little. A benchmark is a fixed test, and a fixed test has a short, predictable lifespan: models climb it until it can no longer tell them apart, it leaks into training data and stops measuring anything, and even at its freshest it captures one narrow slice of ability that may have nothing to do with what you need a model for this upcoming Tuesday. The failure isn't that any given benchmark is bad, but that a static artifact cannot track a moving target — and "which model is best for me" is about as non-stationary as targets get. You’ll need something that keeps moving and adapting with the target itself.
The only honest way to settle "which model is better" is to gather the examples where the models disagree and see which one holds up. Gathering that collection is not a step toward the answer — it is the answer. In other words, the evaluation set and the verdict are the same object; the evidence isn't commentary on the result, it is the result.
A small example makes it concrete. Four models sit on a leaderboard, and their averages on static evals crown Model A as “best”. You are not choosing a model in the abstract, though — you are choosing one for your specific task. Now someone surfaces a single question, the kind of nasty edge case that actually comes up in your work, that Model A answers confidently yet wrong, that Model B gets right, and that Models C and D also miss. That one example is worth more to your decision than Model A's lead in the standings, because it shows you exactly where A breaks and that B covers the gap — the very thing the average buried.
That example reveals which evidence is worth most for model evaluations: the most discriminating one; a question only a few models get right while the rest get it wrong. A question every model aces tells you nothing about their capabilities, and a question every model flunks also tells you nothing; the value lives in the split, and it peaks when a question is a needle that only one model can thread. (The precise version, given in the paper, is just as plain: score a question by how many models it stumps over how many it doesn't, and give no credit when nobody gets it right.)
Now motivated, our problem turns practical. How do you get a crowd to go and find those splitting questions, and pay them fairly for the ones that matter? That is precisely what evidence markets are designed to do — for LLM evals and beyond.
Model evaluation is amongst the sharpest cases, but not the only one. The same skeleton fits any question that is comparative and has to be answered from assembled evidence rather time. The following table highlights some motivating examples:
| Question | A "unit" of evidence | What "quality" means |
|---|---|---|
| Which model is better for this task? | A prompt with the expected and observed outputs | It separates and distinguishes models |
| Will this result replicate? | A replication attempt, its protocol and result | It bears directly on the original claim |
| Did this policy work? | A study, natural experiment, or administrative dataset | It is a credible signal about the causal effect |
| Which tool fits our workload? | A task-specific test case | It predicts performance on the actual job |
We place evaluation at the top of this list for a reason. The assembled question set literally forms the verdict, so there is no gap between the evidence and the answer. Moving down the rows widens the gap — for example, a pile of replication studies still has to be judged into a "yes" or a "no" — and closing that gap is work the verifier, later, has to do.
If you work in AI, you may already be familiar with an earlier version of this. A benchmark asks how models did on a fixed test; a bias bounty asks whether anyone can find a real failure. An evidence market is akin to a standing, dynamic, and priced bias bounty; it pays people to surface failures, pays the most when a failure discriminates between alternatives, and leaves the failures behind as a reusable test. It is the same idea, but with a live price on it that gels incentives it needs to function. The question it runs into — who validates the failures — is what the back half of this post is about.
Paying for beliefs and evidence
Before progressing further, we'll make it concrete with one market from start to finish. Someone escrows liquidity to create a market on a real question: for reviewing indemnification clauses in contracts, is GPT-5 or Claude Opus 4.6 the better tool? A litigator who has never bet a dollar in her life — and has no intention of starting — submits a single clause that GPT-5 confidently misreads and Claude gets right, the kind of split that summary statistics like an average can bury. She is paid for that clause from the escrowed liquidity, and she walks away holding no position at all. A trader who thinks Claude will come out ahead can buy shares the ordinary way, as they would in any standard prediction market. As more clauses like the litigator's accumulate — the discriminating ones, not the ones every model handles — the price sharpens on less and less capital. When enough evidence has piled up, the market resolves on the set the crowd assembled. What is left behind after resolution is a contract-review evaluation set that the whole field can reuse.
That short example introduces three moves a trader can take in a market, which strictly expands on what standard prediction market allow. You can do the familiar thing and take a position on the outcome. You can also submit evidence, e.g. a prompt, a test case, a replication result, or any checkable artifact that bears on the answer. Finally, you can take both actions at once. The first action and its payout mechanism will be familiar to traders engaging with existing prediction markets, whereas that second action (evidence submission) is now paid in its own right.
This unbundling is at the center of the design. A standard prediction market makes you bring three things to get paid: a belief about the outcome, the capital to take a position reflecting it, and the risk appetite to bet on it. Evidence markets pull these apart. You can be paid for knowing something without being paid for betting on it, which is exactly the seat a risk-averse expert never had. Importantly, a bettor who cares only about the price wins too. In a standard, belief-only market all you can read off your rivals is the number they pushed the price to, and you have to reverse-engineer what they knew; here the evidence sits in the open, so the next trader updates on it directly and the price is built on a record everyone can see.
So, digging deeper, how do you pay someone for their evidence? Underpinning an evidence market is a market scoring rule — a long-standing design for eliciting forecasts from crowds — and we change one thing about how they pay.
Picture the market scoring rule as a curve running from the probability you submit to the score you collect. The mechanic is relative, wherein you are paid the difference between how well your probability fits the eventual outcome versus how well the previous trader's did. Move the price toward the truth and you collect payout; push it the wrong way and you pay. An ordinary market keeps that curve fixed and lets you climb it only by moving the price. By contrast, an evidence market lets the curve itself move. As quality evidence accumulates, the curve lifts, and lifting it hands money to whomever supplied that evidence, whether or not they ever touch the price. (Note that what counts as "quality" is defined per market to match its needs; the “split-the-field” score discussed in the last section is one option, but not the only one.)
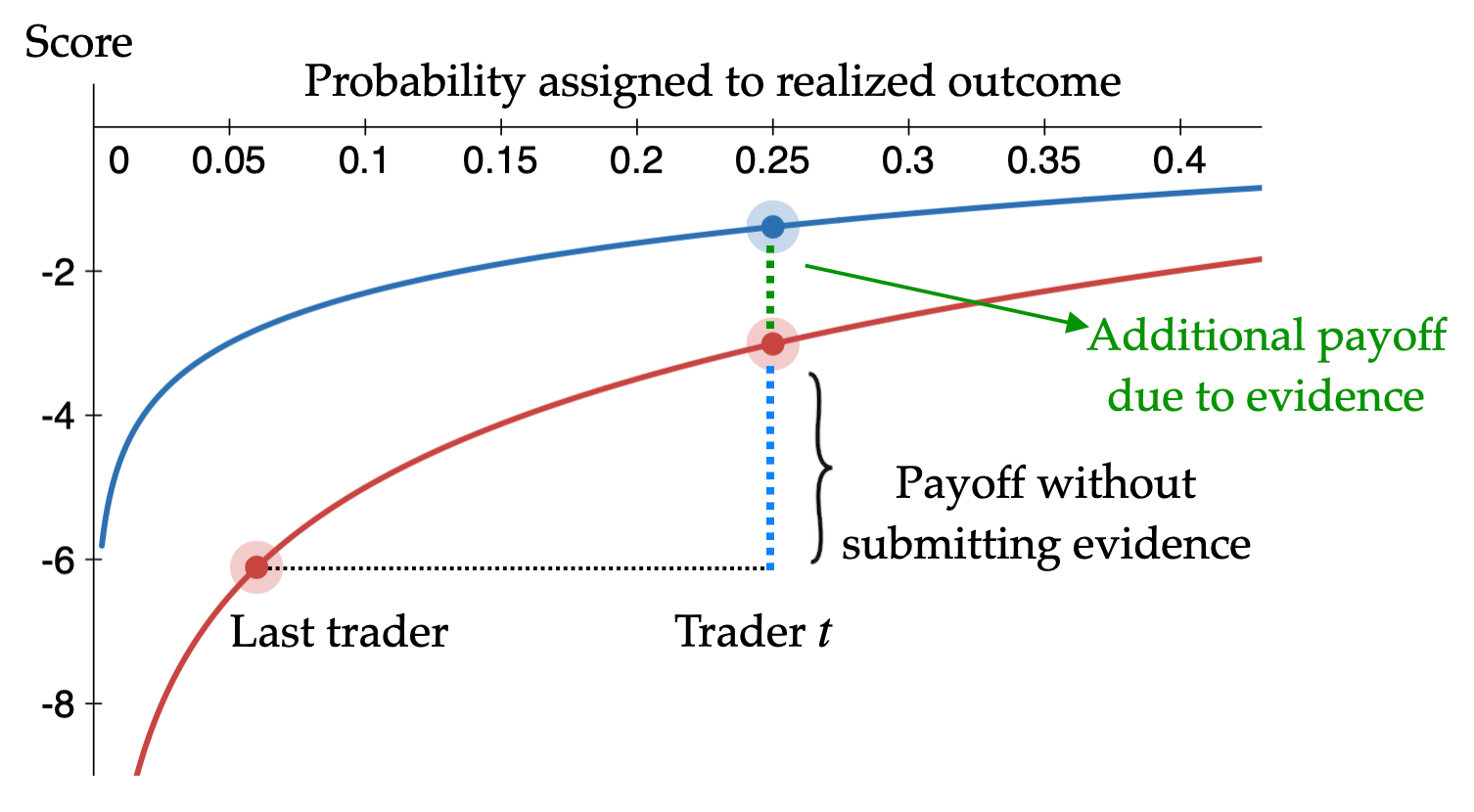
Two things follow, and neither was incorporated into the mechanism design by hand. First, the reward for evidence does not depend on taking a side; you can collect it without placing a bet. This is not a rule we bolted on for risk-averse experts. Rather, it fell out of designing around the curvature "for free". The reward for moving the curve up does not depend on which side, if any, you took. Second, the size of that reward rises and falls with how uncertain the market is. When the crowd is torn, a good piece of evidence is worth a great deal; when the question is all but settled, the same piece is worth almost nothing. The market pays the most for evidence exactly when it knows the least. None of this is free money. The market's creator is a subsidized market-maker spending a bounded budget to pull information out of the crowd; their bet is that, for the questions worth running, the evidence gathered is worth the subsidy.
An equivalent, but alternative framing:
Buying shares moves the price; supplying evidence steepens the curve those shares move along, so the same belief shift takes fewer shares. Evidence and capital become substitutes for moving the price — which is why a contribution of pure evidence and a purchase of shares are, under the hood, the same kind of act.
Everything so far pays for evidence whether the market eventually settles on an outside event or on the evidence itself. The latter case is the radical one, so it is worth being precise about how evidence settles anything at all. The collected evidence is the answer you read off directly — e.g., which model covers which gaps, where each one breaks, the whole assembled record. The market settles separately as a function of the collected evidence, via a distribution weighted toward whatever the evidence most supports. Observe our emphasis on the market settling via “a distribution”, and not a hard winner-take-all; doing so leaves participants' expected payoff untouched, while a single knob — a temperature on how it's drawn — shrinks how much influence anyone can hold over the result by holding evidence back.
There is an honest tension here, worth naming rather than brushing aside. That same knob that stops an "evidence whale" from tilting the outcome also makes the draw blunter, and (unlike a market that resolves on an outside event) the beliefs here need not sharpen as you approach the close. The tension dissolves once you separate two things the design explicitly keeps disjointed. The outcome lottery is only the payout engine, and it is allowed to be noisy. The answer is read off the assembled evidence directly — the argmax of the scores, e.g. the full record of which model covers which gap — and that reading does not care how blunt the draw was. The market's job is to fund and assemble the evidence; the outcome lottery does not have to be sharp to do it.
It is easy to mistake resolving on the evidence for a niche trick. But it’s better to see it as a dial — a choice about when, and on what basis, you take your answer. Sometimes nature will never hand you one, e.g. which model is better, whether a study replicates, whether a policy worked. Sometimes nature will answer, but only on a timeline no one can wait for. A team choosing between two model providers this quarter cannot hold out for a definitive benchmark that may never arrive; a funder deciding whether to keep backing a replication effort cannot wait two years for the literature to settle. In both cases you want the best answer the available evidence supports now, not the one nature gets around to revealing later. Similarly, when it finally arrives, sometimes nature's answer will be contested or never made fully public, and resolving on evidence anyone can inspect beats waiting on a verdict you would have to take on faith.
That last case should sound familiar, because it is closer to today's status quo than it looks. Some of the biggest, most popular markets being trusted en masse are resolved through oracles, and an oracle is an adjudication, not a window onto the world — a cruder form of the very thing we are formalizing. More on that shortly.
An aside for the mechanism-design readers:
Reporting your true belief and submitting your full evidence set is a dominant strategy when the market resolves on an outside event, and approximately so when it resolves on its own evidence; the approximation is governed by a temperature on how the resolution is drawn from the evidence-weighted distribution, and turning it up shrinks toward zero how much anyone can move the outcome by withholding. The platform's worst-case loss is capped at a fixed multiple of the log of the number of outcomes (near identical to LMSR), so the market has a known, bounded cost to run. The whole mechanism can be implemented as an automated market maker with identical incentives — so it can trade like the venues people already use.
Evidence markets are not an incremental improvement on the markets we've grown used to seeing on Kalshi and Polymarket. It is a different instrument altogether; one that resolves on the timeline you choose, settles on evidence anyone can check, and carries the reasoning alongside the price. It is a market built for the people who left — the ones who knew something but had no bet-shaped way to say it, or no appetite to wager on it even if they did. Which raises the question the next section is about: once the crowd has assembled all that evidence, what is it worth?
The weight of evidence is cumulative
There's a deflating way to describe any market: it just moves money around. Winners are paid, losers pay, and at the close it nets to zero for everyone who wasn't in it. By that account, asking a market to leave the rest of us better off is sentimental. Redistribution and price discovery are the job, and the job is done when the bell rings.
A standard prediction market earns that description. While it runs, the live price is worth something to onlookers; the moment it resolves, the one thing it produced (i.e., a probability) decays into a line on a chart. Whatever was learned stays with the people who traded. For everyone outside, the lasting residue is close to nothing.
An evidence market closes differently. When the trading stops, the evidence the crowd assembled is still there. For something like model evaluation, that residue is a reusable test — a set of discriminating questions and documented failures the whole field can pick up, long after the last trade cleared. Collect enough of those, and the market has gone beyond simply naming a winner into producing an artifact the rest of us can use.
For a question the world will eventually settle on its own, the assembled evidence is a bonus riding on top of a price that would have resolved anyway. For the questions nature won’t settle with the passage of time alone, there is no price that would have resolved anyway — the evidence is the entire output, and it is an artifact we could not build before with the same incentive-backed hardening.
The case for these markets was never that traders make sharper forecasts, standard prediction markets already solved for that. It is that the act of forecasting both supplements and funds the construction of something with utility beyond any single market. Speculation, pointed the right way, becomes a subsidy for public knowledge — a market that leaves the rest of us better informed than it found us.
That is a large claim, and we will come back to how far it reaches. First, we address objections a fair reader may have.
Why not just…
We’ve introduced a lot of heavy machinery, but couldn’t we get most of the way to the same solution with something simpler? It’s a fair challenge. Evidence markets add unconventional moving parts, and good mechanism design must earn its complexity rather than assuming it. So take the simpler alternatives in turn.
Couldn't you just ask traders for their reasons? You could, but explaining a price is not the same as resolving one, and a trader with a sharp view but no novel argument to attach is left with nowhere to stand. Couldn't you keep the prediction market and bolt on a bounty for good examples? A flat bounty pays the same for a needle vs a dud while still leaving the question itself hanging, i.e. the evidence sits beside the answer rather than becoming it. Couldn't you use a conditional or decision market, the kind built to inform choices? Those are richer questions than standard prediction markets wrangle with, but they still need an outside event to resolve against and still hand you a price at the end; both limitations we started with survive intact. Couldn't you let the crowd vouch for each other's evidence (e.g. peer prediction)? Anyone qualified to judge a submission is also a potential trader with a stake in the verdict, and a judge with a position is not a reliable judge.
The cleanest objection is the most interesting, because it dissolves on contact. Why resolve on evidence at all — why not resolve externally, the way real markets do, and read the answer off the world? The catch is in the word "externally." Most on-chain markets resolve through an oracle, and an oracle is not nature; it is an institution for deciding what counts as nature's answer. UMA, the optimistic oracle that resolves much of Polymarket, settles disputed questions by a stake-weighted vote with an appeal window — a verdict assembled from what token-holders assert and are willing to back, arrived at well after the fact. When the question is clean, this is invisible. When it is not, the adjudication shows. For example, in mid-2025 a Polymarket market on whether Zelenskyy had worn a suit, with hundreds of millions of dollars riding on it, flipped from "yes" to "no" over nine days of disputes, settled by a token-weighted vote that a menswear expert could call only technically defensible. That is endogenous resolution already, but deferred, contested, and stripped of guarantees. We are not proposing an exotic new way to settle a question in this work. We are making principled something the most active markets already do on faith.
None of this makes evidence markets the right tool everywhere, and it’s worth being just as clear about where they are not appropriate. If a question resolves cheaply, soon, and uncontroversially and all you want is the bet, use a plain prediction market — the evidence machinery is dead weight. A question that cannot be broken into atomic, checkable pieces of evidence gives the mechanism nothing to score. In a similar vein, if no judge (human, model, or otherwise) can affordably tell real evidence from fabricated, then the whole design rests on a foundation that is not there; this is where the hardest open problem lives, and it is where we turn next.
Adjudicating evidence: sifting fact from faux
Pay people for evidence and you have handed them a reason to manufacture it — to flood the market with the irrelevant, the duplicated, and the outright fabricated. Since evidence also settles the question, a convincing fake not only skims a payout but can also bend the final answer. Therefore, the market's whole credibility rests on one capability: telling real evidence from fake.
A natural instinct is to let the crowd police itself, each participant vouching for or flagging the others. It does not hold up, for the reason we flagged a moment ago: anyone qualified to judge a submission is also a potential trader with a stake in the verdict.
Our approach leans on a tool that did not exist a few years ago. A capable model makes the first call on each submission — accept or reject, with its reasoning. Anyone who thinks it got the call wrong can challenge by staking money; win the dispute and you are paid, lose it and your stake is forfeit. The design swaps "trust people to be honest" for "make honesty the profitable move," and it rides an asymmetry that has held up across recent work: checking whether a piece of evidence holds up is far easier than producing it. This will look familiar from the last section — the same optimistic, dispute-by-staking flavor an oracle like UMA already has. The difference is the arbiter. Instead of a token-holder vote arriving after the fact, the first call is made by a model that can read the entire evidence record, and a challenge is settled by credibly neutral re-adjudication with the original verdict, its reasoning, and the challenger's counter-argument all in view — not by counting tokens.
We are not pretending this is a finished facet of our work on evidence markets. The judge model is a single point of failure, and an adversarial market with real money on it will probe it harder than any benchmark. Regardless, we believe an approach in this vein is worth betting on for two reasons: (i) models are getting better at exactly this kind of checking, and we expect that to continue; (ii) a judge model’s errors can be supplemented with clever design over dispute mechanisms (more on this in a forthcoming announcement about a complementary line of research we’ve been pursuing in parallel).
Conclusion
The open questions are real, and non-trivial when we look towards taking these markets from research into production with general permissionless market creation. Beyond designing robust and efficient evidence adjudication oracles as discussed in the previous section, identifying appropriate evidence scoring functions (i.e. how we decide the “quality” of a piece of evidence) largely depends on the use cases evidence markets are being applied to. Furthermore, running one of these markets means rebuilding trading interfaces from the ground up. We'd rather name these bluntly, alongside others mentioned in the full paper, than hand-wave them away.
The prediction-market framing is, in the end, too small. What this work sketches is a way to fund knowledge that individuals likely wouldn’t pay to produce alone — market-funded epistemic public goods, where the speculation is the subsidy and the evidence is the point. That future is not automatic. The public good only exists if the evidence is released rather than locked away — a choice the people who build these markets have to make. But the mechanism makes it reachable, and the questions it could carry — which model, which study, which policy — are precisely the ones we most struggle to answer today.
Evidence markets do not replace the prediction market; they generalize it. Take the evidence away and you are left with precisely the market you started with — a standard prediction market is one corner of this design, where nobody brought any evidence. The rest of the design is the space we opened up for the people who never had sufficient reason to show up. A market that returns a price tells you what people were willing to bet on. A market that returns evidence tells you what they learned. We believe the second is worth building.
The paper gives the formal mechanism: https://arxiv.org/abs/2606.07434