Look Beyond One-Size-Fits-All LLMs with IR3DE
We propose IR3DE, a lightweight router that directs prompts to the most suitable domain experts based on token embeddings. IR3DE enables the addition or removal of experts with minimal updates, avoiding the need to rebuild the router. As a result, it is highly suitable for decentralised settings.

With the increasing number of available LLMs, the importance of choosing the most suitable model for each user prompt is growing fast. While many generalist models are available, they often perform worse than specialised, task-specific expert LLMs. As a result, researchers have begun exploring methods to route each prompt to the most appropriate expert model. To this end, they propose using routers, whose purpose is to determine which expert is best suited to handle the incoming prompt. You can think of it as a smart dispatcher. When a request is received, the router classifies it based on factors such as complexity, expected output length, required capabilities, latency sensitivity, or monetary budget constraints. It then forwards the prompt to the model that is most capable of completing the task effectively.
We introduce one such router: Ridge Regression Router for Domain Experts (IR3DE). For IR3DE, the most appropriate expert for each prompt is the one whose domain most closely matches the prompt domain. For instance, in the following picture, we depict a scenario with three experts: a math expert, a biology expert, and a coding expert. IR3DE can route even prompts whose domain is ambiguous to the most appropriate expert.
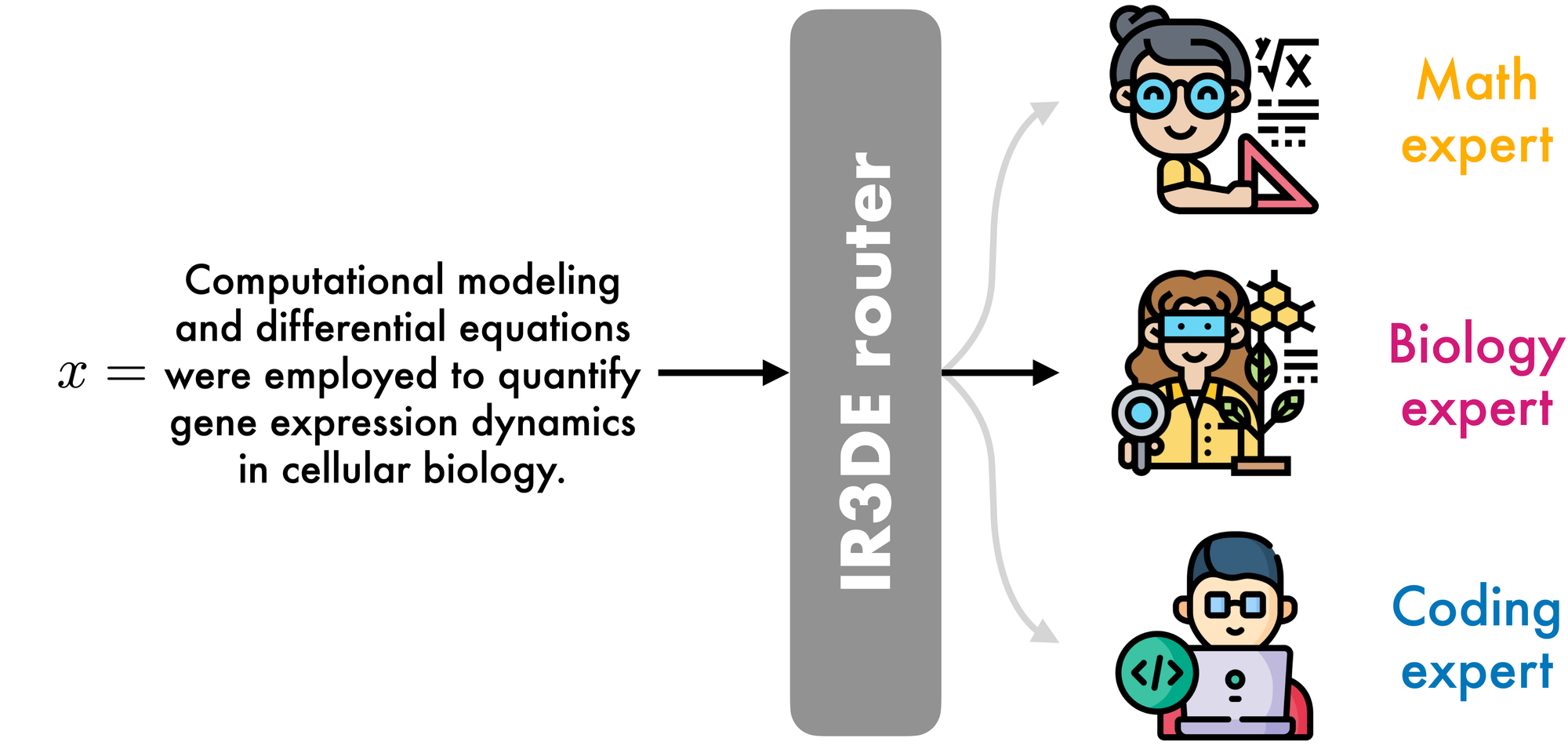
In contrast to other routing mechanisms, IR3DE uniquely prioritises matching each prompt with the most suitable expert based on domain expertise. This approach maximises routing accuracy while avoiding interference with independent objectives pursued by other routers in the literature, such as minimising costs or latency.
We evaluated IR3DE both in Causal Language Modeling settings, where the task is next token prediction and the models are evaluated with perplexity score, and in a Reasoning setting, where the objectives can vary depending on the task, and the models are required to exhibit complex reasoning capabilities (such as solving mathematical problems, writing code, or carefully following the instructions of the user).
We compared IR3DE with the following baselines:
- Experts average: this is not a router, but the performance of the model obtained by averaging all the experts.
- Random router: each prompt is forwarded to a random expert, independently from its content.
- MoDEM: MoDEM router using a DeBERTa v3 model to extract feature representations of each prompt. Similarly to IR3DE, the objective of this router is solely to maximise routing accuracy of each prompt to the most appropriate domain expert.
- kNN router: one of the proposed routers in PolyRouter, using a BERT model and a kNN strategy to match each test prompt to the nearest domain.
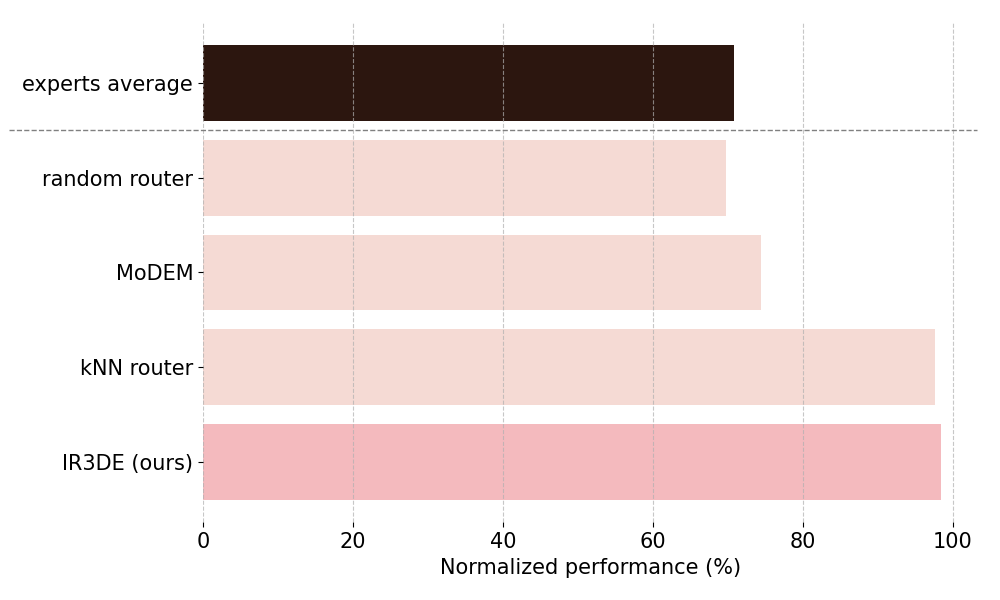
Figure 2 below shows how, in our Reasoning setting with four expert models belonging to the domains math, coding, instruction following, and multilingual, IR3DE delivers superior average normalised performance compared with the baselines. Notably, IR3DE even surpasses the kNN router baseline from PolyRouter, which requires an additional BERT model to extract feature vectors for each prompt, thereby substantially increasing routing costs compared with IR3DE.
How IR3DE works
IR3DE is designed with cost efficiency in mind. It consists of only three components: a lookup table and two linear layers, resulting in a relatively small number of parameters that don’t even need to be trained and can be used directly for inference. Specifically, IR3DE comprises a tokeniser \(\mathcal{T}\), a pre-trained embedding layer \(\mathcal{E}\), and a token router \(f\) parameterised by weights \(W\). Notably, IR3DE works with any choice of \(\mathcal{T}\) and \(\mathcal{E}\), which can be different from the tokeniser and embedding layer used by the experts. Therefore, \(\mathcal{T}\) and \(\mathcal{E}\) are given (they can, for instance, be downloaded from any pre-trained model on HuggingFace), while the only prerequisite to use IR3DE is to find suitable weights \(W\) for the token router.
Although the final objective of IR3DE is to route each prompt to the most appropriate expert, the token router's purpose is to classify each token into its closest corresponding domain. To this end, IR3DE computes the token router weights asynchronously, exploiting the properties of Ridge Regression (RR). Generally speaking, suppose you have access to a labeled dataset with samples \((x, y)\). The RR objective is to find parameters \(W\) for a linear predictor \(f(x; W)= W^\top x\) by minimising Regularised Least Squares error between the soft probabilities of \(f\) and the one-hot encoding vectors of \(y\). Using \(\mathcal{T}\) and \(\mathcal{E}\), IR3DE extracts token embeddings and, together with the associated domain labels for each prompt, computes optimal RR weights using the RR closed-form solution, which avoids gradient-based, stochastic training to compute \(W\), thus largely reducing training costs. (see Figure 3).
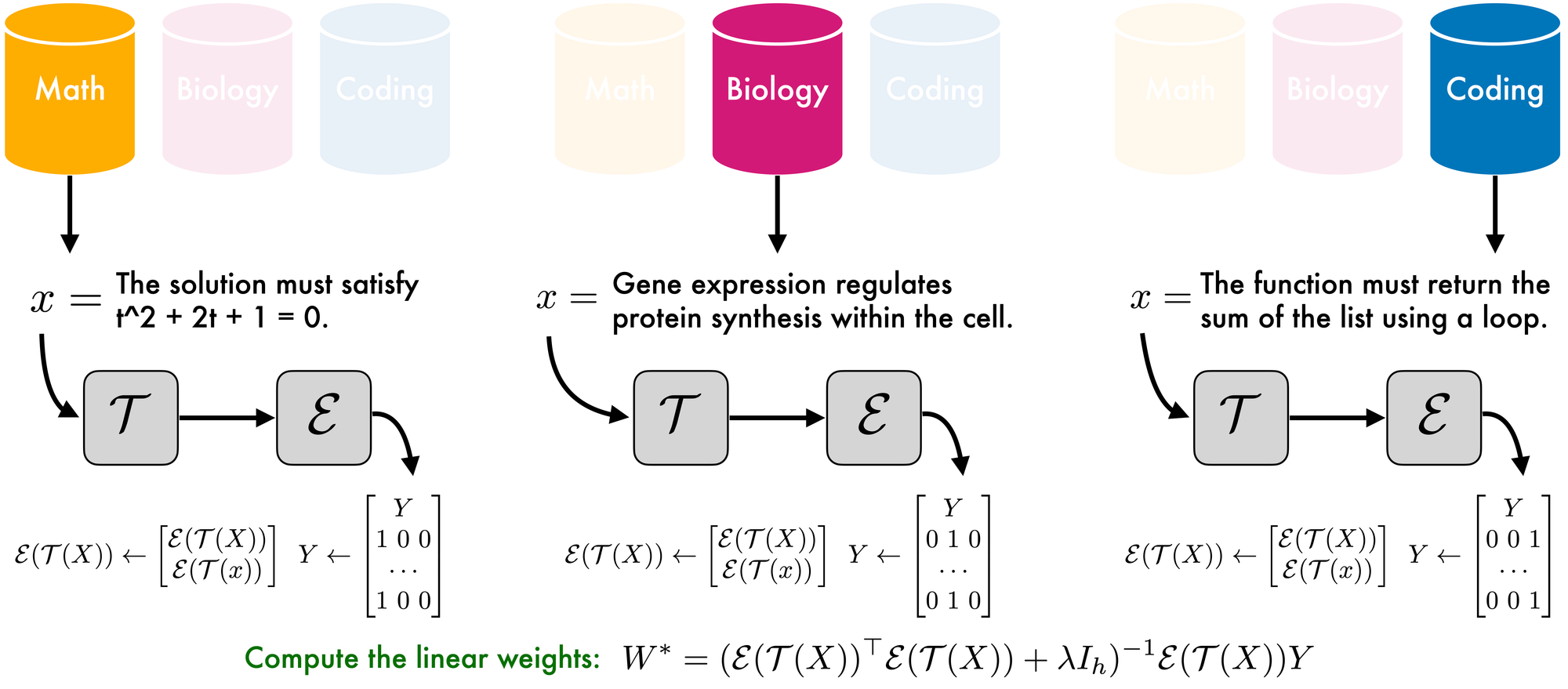
The optimal weights are very cheap to compute, as they involve only two matrix multiplications and a matrix inversion (typically a ~1k-by-1k matrix).
IR3DE token router construction in distributed or decentralised settings
Ridge regression allows statistics to be collected asynchronously and aggregated later to compute the final solution. This property is highly desirable in distributed or decentralised settings where privacy matters or communication is a bottleneck, as it avoids sharing data among participating nodes.
This property can be exploited in IR3DE by computing local RR matrices at each node using only the local domain dataset, then aggregating these statistics to compute the final optimal weights with the closed-form RR solution. Moreover, it also allows new domain experts to join or existing ones to leave at any time by incrementally updating the RR statistics.
Routing criterion
For any given prompt \(x\), the token router of IR3DE predicts a possible domain for each token of \(x\). These predictions can be interpreted as votes cast by each token. The final expert is selected as the domain receiving the highest number of ballots. To suppress votes from uncertain tokens, we retain only those cast by the top-k tokens with the lowest Shannon entropy in their softmax probability distributions (see Figure 4).
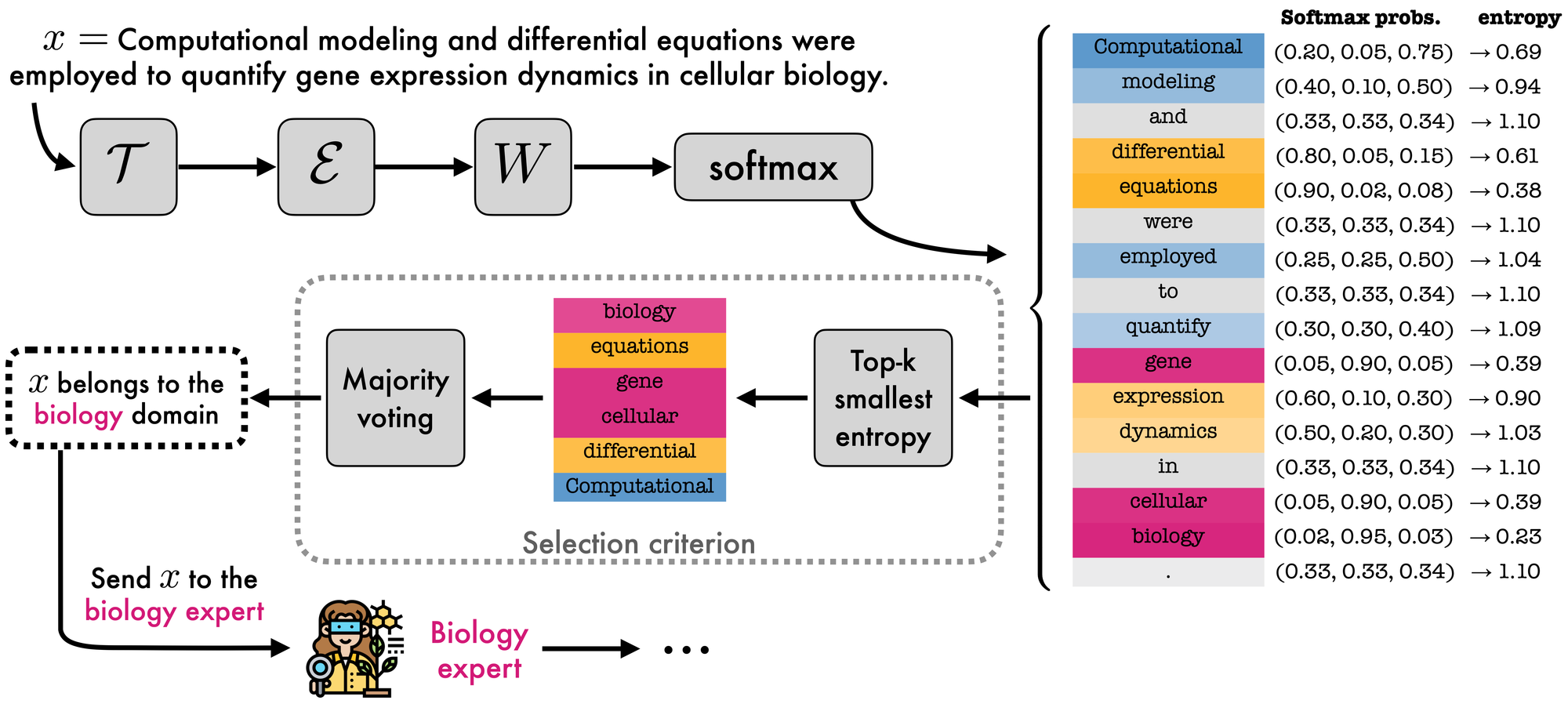
Specifically, the input samples are first forwarded to the token router to extract softmax probabilities for each token. Next, the Shannon entropy of each token’s probabilities is computed, and only the top-k tokens with the lowest entropy are retained (in the image, k=6). Finally, each remaining token casts a vote to select the expert to which \(x\) will be forwarded.
The design rationale for the entropy-based router, which doesn’t allow all tokens to participate in majority voting and instead filters out undecided tokens from the ballots, is that such tokens lead to uncertain predictions. Indeed, the same tokens might appear with different domain labels depending on the prompts in which they appear. This lack of specificity means the tokens are insufficiently discriminative to determine which domain a given prompt belongs to. For example, the tokens “of” or “to” are likely to appear across all domains. Consequently, this leads to uncertain predictions for the tokens “of” or “to” from the token router, and this uncertainty can be easily detected using Shannon entropy.
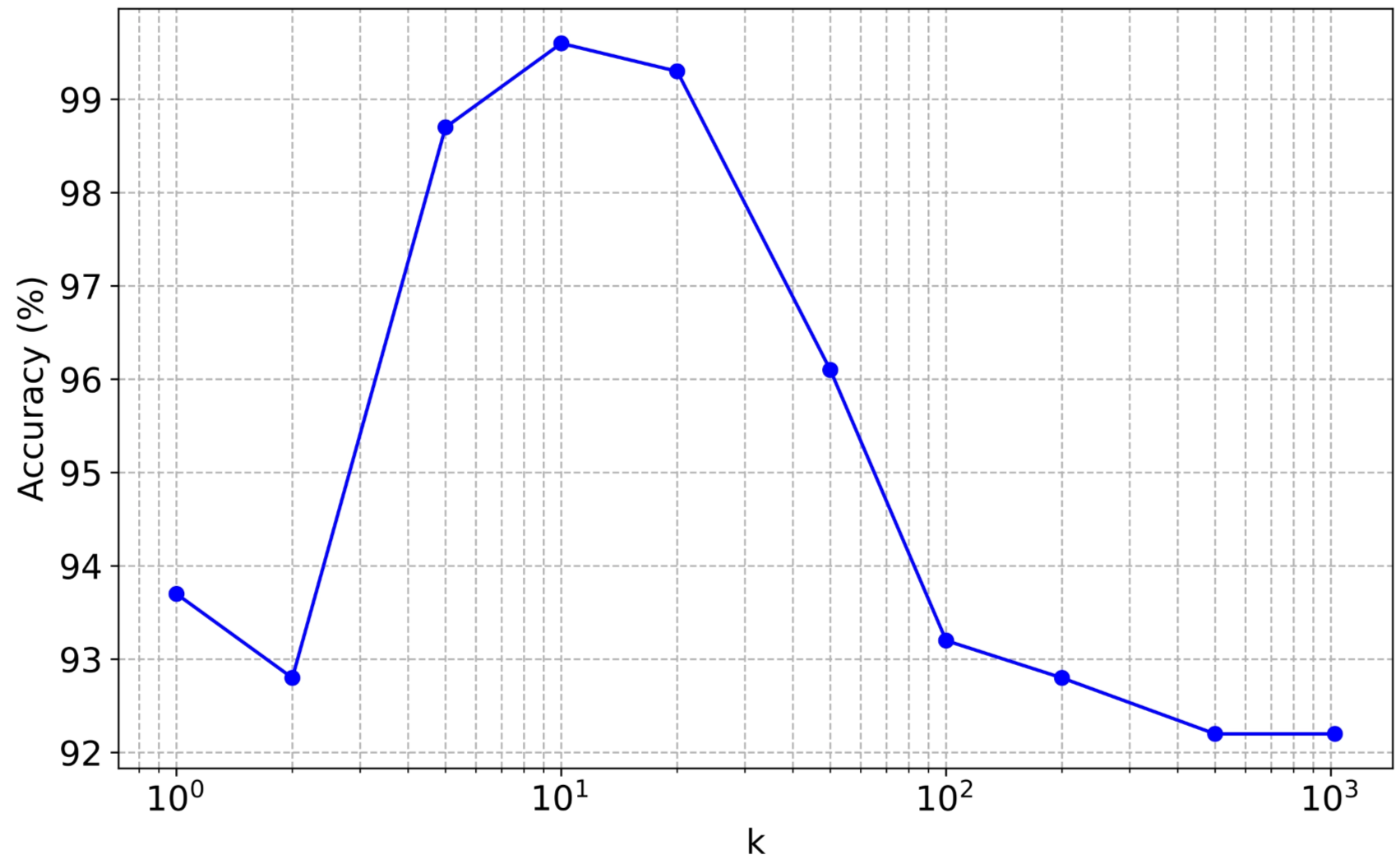
In Figure 5 below, we also empirically show the benefits of filtering out uncertain votes. Including too many tokens in the election leads to decreasing routing accuracy. Similarly, allowing only the most confident token or the two most confident tokens (i.e., the tokens with the lowest entropy) leads to lower routing accuracy, as a single token or even two may not be sufficient to characterise an entire prompt.
Why IR3DE matters and future work
Despite being a linear router, IR3DE achieves performance comparable to or superior to other baselines across all settings. Prior work on prompt-to-domain-expert routing often relies on additional language models. This increases routing costs and typically requires access to unified domain datasets for training, which can raise privacy concerns. Conversely, IR3DE is a lightweight, adaptable routing method that provides a strong foundation for efficient, modular, and cost-effective routing mechanisms that can seamlessly direct each prompt to the most appropriate expert.
Future versions of IR3DE may explicitly incorporate system-level costs into the routing objective, accounting not only for predictive performance but also for computation, latency, and memory usage, thereby enabling more practical deployment in resource-constrained settings.
View the GitHub Repo here: https://github.com/gensyn-ai/IR3DE
Read the full research paper here: https://arxiv.org/abs/2606.06098