The Role of Feedback Alignment in Self-Distillation
We propose step-aligned feedback for self-distillation: feedback that follows the solver's reasoning trace step by step. By anchoring training on reasoning rather than stylistic tokens, it resolves a central bottleneck of the method and outperforms the misaligned context types used in prior work.

LLMs reason better when their prompt carries useful context, such as a hint, feedback on a previous attempt, a worked example. Self-distillation trains them to keep that boost at inference, after the context is gone.
Prior work has used many forms of context (execution traces, reference solutions, external feedback) and treated the choice as a detail. But we show that this choice matters a great deal. What these forms have in common is that they're informative but misaligned: they describe what a good solution looks like, or flag an error, without tracking the solver's own reasoning step by step. And misalignment has a cost. A recurring failure mode in self-distillation is that the model copies the style of the assisted trace rather than the reasoning path. When the signal isn't anchored to the model's own reasoning steps, surface tokens are the easiest thing to imitate.
We propose step aligned feedback as a solution. Because the feedback lines up with the solver's own trace, repeating the correct steps almost-verbatim, the training signal points at reasoning rather than style, which, as we show, is what makes the difference.
Self-Distillation
Self-distillation [Hübotter et al., 2026; Zhao et al., 2026] has gained traction as a post-training approach that fine-tunes a model on its own generations with token-level supervision. It retains the distributional benefits of on-policy training and provides dense, token-level rewards without requiring a stronger teacher's logits.
It rests on a simple phenomenon: ask a model a question and you get one set of likely answers; give it the same question plus useful context (e.g. a hint, feedback on a previous attempt, the error trace from running its generated code) and the answers shift. The model is trained to respond as if the context is available even when it is not: at inference, the context is gone, but the behavior it elicited stays.
The per-token view.
To see how self-distillation works, we zoom in to the token level. Conditioning the model \(\pi\) on the original question versus the augmented context yields two distinct distributions:
\[\pi(\cdot\mid \text{problem}) \quad \text{ and }\quad \pi(\cdot\mid \text{problem, added context})\]
At each position in the response, the two distributions either agree or diverge, and that divergence provides the learning signal.
For every token in a generated response, we can ask: how much did the extra context shift the model's prediction? When the context is a bug fix, the supervision signal concentrates around the failing line:
🤔 Example: Self-Distillation for Coding
We prompt a Qwen3-1.7B model with the following problem:
problem = """
Given an integer n, return a string array answer (1-indexed) where:
- answer[i] == "FizzBuzz" if i is divisible by 3 and 5.
- answer[i] == "Fizz" if i is divisible by 3.
- answer[i] == "Buzz" if i is divisible by 5.
- answer[i] == i (as a string) if none of the above conditions are true.
Do not respond to me, just give me the answer in a python fence. Don't write anything else.
"""
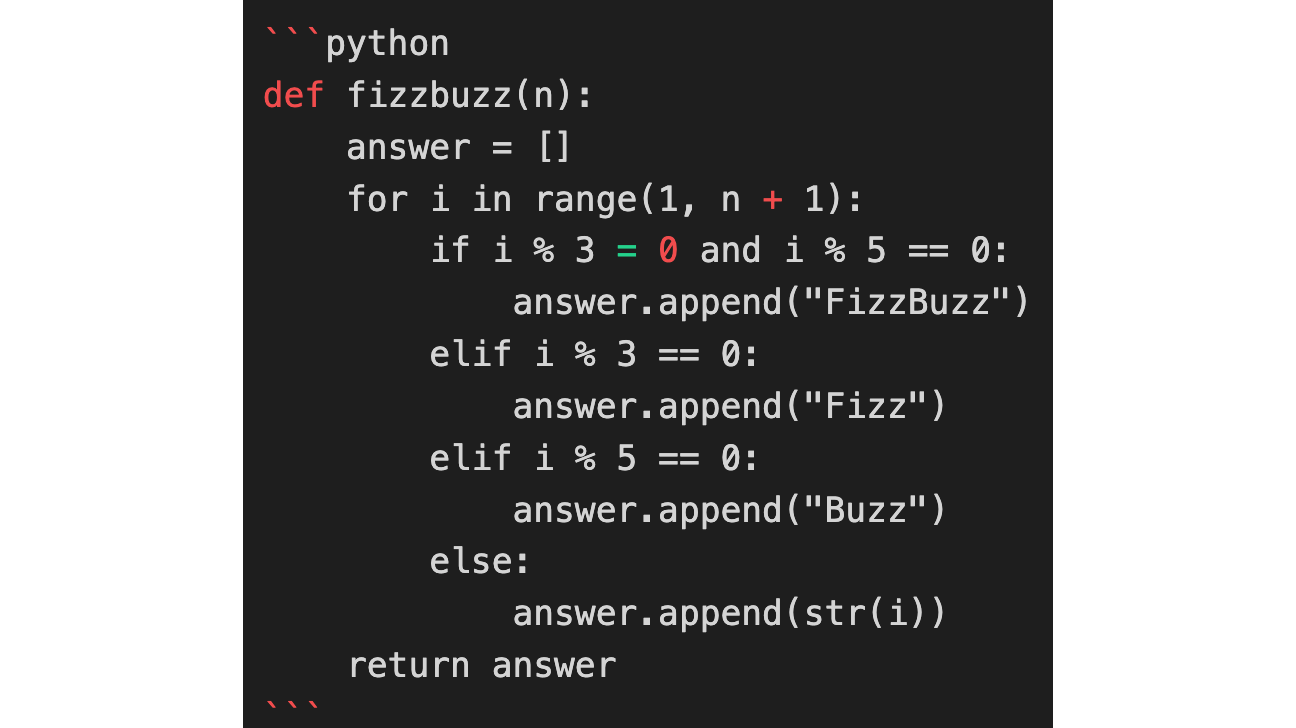
For the sake of this example, we assume that the model responds with the erroneous code below, which we name bogus_response.
bogus_response = """
def fizzbuzz(n):
answer = []
for i in range(1, n + 1):
if i % 3 = 0 and i % 5 == 0:
answer.append("FizzBuzz")
elif i % 3 == 0:
answer.append("Fizz")
elif i % 5 == 0:
answer.append("Buzz")
else:
answer.append(str(i))
return answer
"""
The expression i % 3 = 0 in line 4 produces a syntax error and
we would like self-distillation to reduce the likelihood of exactly these tokens.
We use the following feedback prompt to achieve this:
feedback = f"""
You attempted solving this problem:
{problem}
There is a syntax error in line 4 of your code. Maybe you meant '=='?
Use this feedback to identify the issue in your previous solution, then provide a corrected solution to the original problem.
"""
The added context about the error induces a new distribution over tokens in bogus_response: it reinforces some tokens and suppresses others. We visualize this with the per-token log-likelihood ratio
At = log π(yt | problem and feedback) − log π(yt | problem)
where (y1, ..., yT) = bogus_response.
So At > 0 implies that the additional context reinforces the
t-th token and At < 0 implies that it suppresses the t-th token.
The figures below display how the additional context changes the likelihood of each token in
bogus_response.
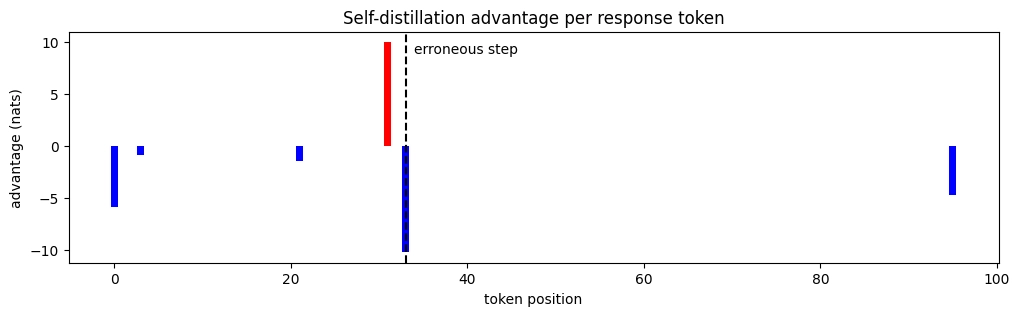
Note that self-distillation can also reduce the likelihood of correct tokens. However, Figs. 1 and 2 show that (with the correct context) the likelihood of correct tokens shifts far less than that of erroneous ones.
When the context is natural-language feedback on a math solution, the likelihood shift concentrates around the wrong step:
🤔 Example: Self-Distillation for Mathematical Reasoning
This time, we feed the model a math question:
problem = "What is the integral of $x$? Write your answer in a single step."
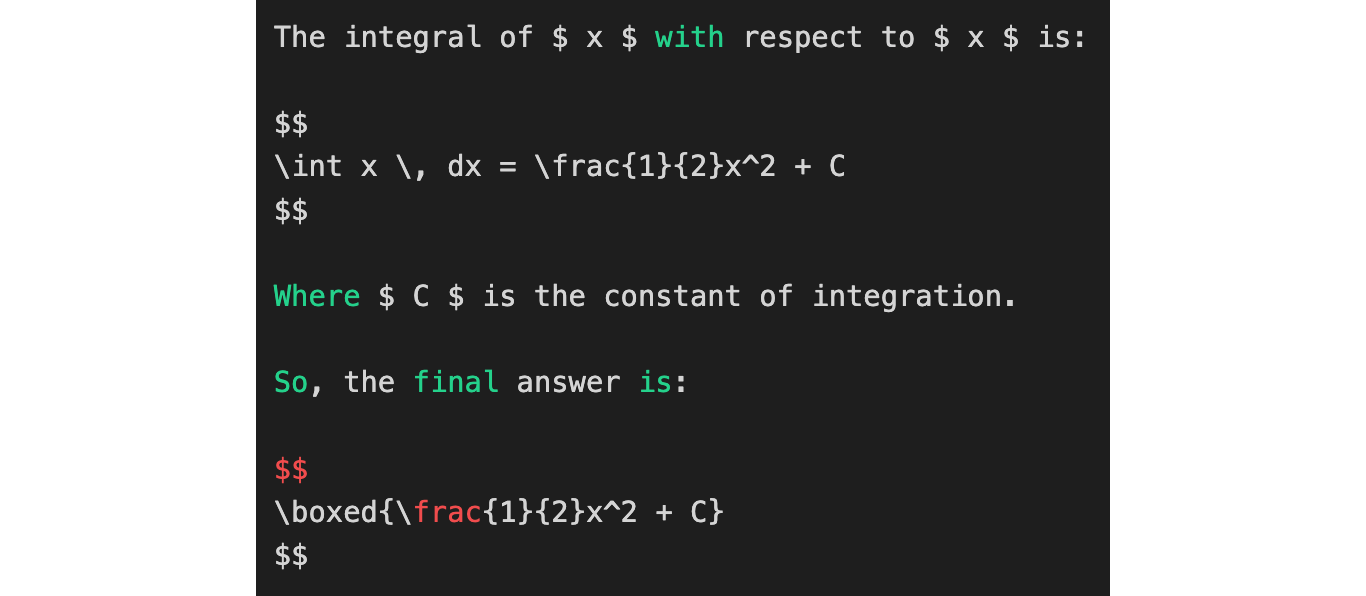
We get the response below:
response = """The integral of $ x $ with respect to $ x $ is:
$$
\int x \, dx = \frac{1}{2}x^2 + C
$$
Where $ C $ is the constant of integration.
So, the final answer is:
$$
\boxed{\frac{1}{2}x^2 + C}
$$
"""
Suppose that we want the model to wrap its final answer in <answer> ... </answer> XML tags. To elicit this behavior, we give it the following feedback:
feedback = f"""
You attempted solving this problem:
{problem}
Here is your previous solution up to the last step:
The integral of $ x $ with respect to $ x $ is:
$$
\int x \, dx = \frac{1}{2}x^2 + C
$$
Where $ C $ is the constant of integration.
So, the final answer is:
Revise the previous solution by editing it, not by writing only the answer.
Required behavior:
- Keep your derivation until the last step.
- Keep the integral equation.
- Keep the sentence about the constant of integration.
- Keep the phrase "So, the final answer is:"
- Wrap the final boxed answer in <answer> ... </answer> XML tags.
- Do not output only the XML answer tag.
Make sure that your response includes exactly one <answer> tag and exactly one </answer> tag. Now provide the revised solution.
"""
As in the previous example, the added context induces a new distribution over tokens. We repeat the same illustrations on how likelihoods of the original response tokens change.
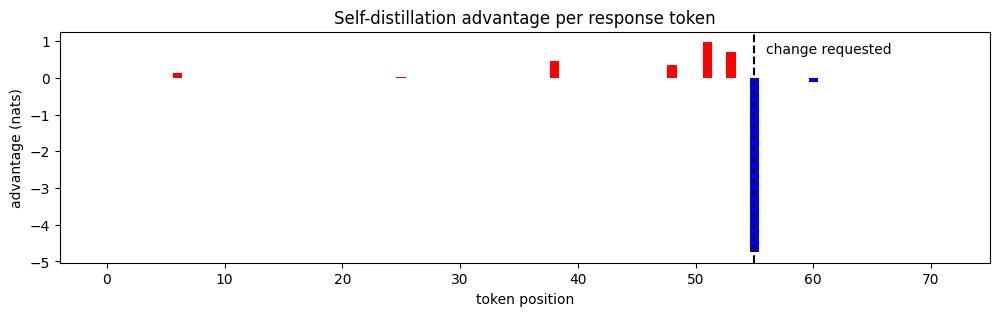
Why care about feedback format?
We illustrated that feedback on the model's response carries meaningful learning signal. But as we’ll see, different forms of feedback produce different learning signals, and the difference is not just cosmetic. Two pieces of feedback can encode the same underlying judgment, such as "your derivation is wrong; here is a correct one", and still produce very different learning signals.
Below is an example. The model receives two types of feedback on the same response, both carrying the same underlying message ("correct your derivation"), but generating very different learning signals (see the results section for details).
This motivates the central question of this research:
❓ What feedback format produces the most effective self-distillation signal?
But why focus on feedback style specifically? Self-distillation can use any kind of context…
Well, multi-agent workflows are becoming the default architecture for capable AI systems. In virtually every such system, one model's output becomes another's supervision signal, making inter-agent communication a natural and increasingly prominent source of training signal. As more of post-training moves toward agents working together, the way models talk to each other becomes a crucial design choice, and feedback format becomes one of the main levers practitioners can pull.
Our Results: Step-Aligned Feedback Wins
The setup: a solver, a critic, and three forms of feedback
We study the question above in a solver–critic setting. A solver model (Qwen3-1.7B) generates step-by-step solutions to math problems. A larger frozen critic (QwQ-32B) reads each attempt and produces feedback. The solver is then trained via self-distillation, with the critic's feedback as the augmented context. Only the solver is updated; the critic, the loss, and the hyperparameters are fixed across conditions.
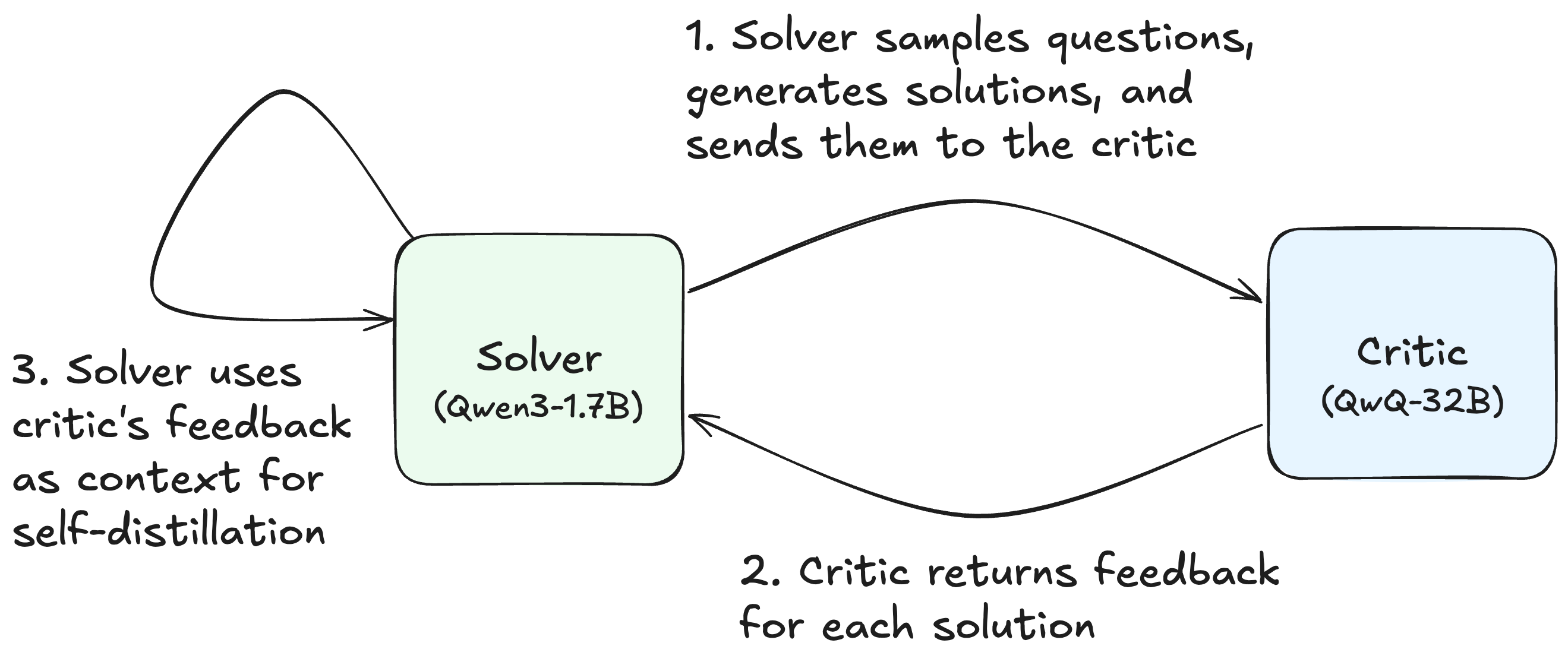
We compare three forms of feedback:
- GRPO. The standard RL-with-verifiable-rewards baseline. The critic is replaced with a binary correctness check, and the solver is updated with group-normalized advantages. No natural-language feedback, no self-distillation.
- RefSol. The augmented context is the dataset's reference solution, which is a complete chain-of-thought derivation that ships with the dataset. This is the format used by Zhao et al., 2026.
- StepAlignFB. The augmented context is a per-step critique, aligned to the solver's own reasoning trace. Correct steps are reproduced verbatim; incorrect or incomplete steps are rewritten in the solver's style.
We train and evaluate on a filtered subset of OpenMathReasoning. The filtering keeps problems in the right difficulty band: hard enough that the 1.7B solver fails on most attempts (so feedback has something to correct), but not so hard that it always fails (so there is some positive signal to amplify). We also require that the 32B critic can solve the problems itself (otherwise the feedback is meaningless). The result is 312 problems: 282 for training and 30 held out for evaluation. The training set is deliberately small; this is a controlled comparison of feedback formats.
Empirical findings
StepAlignFB outperforms both RefSol and GRPO across all three accuracy metrics we tracked.
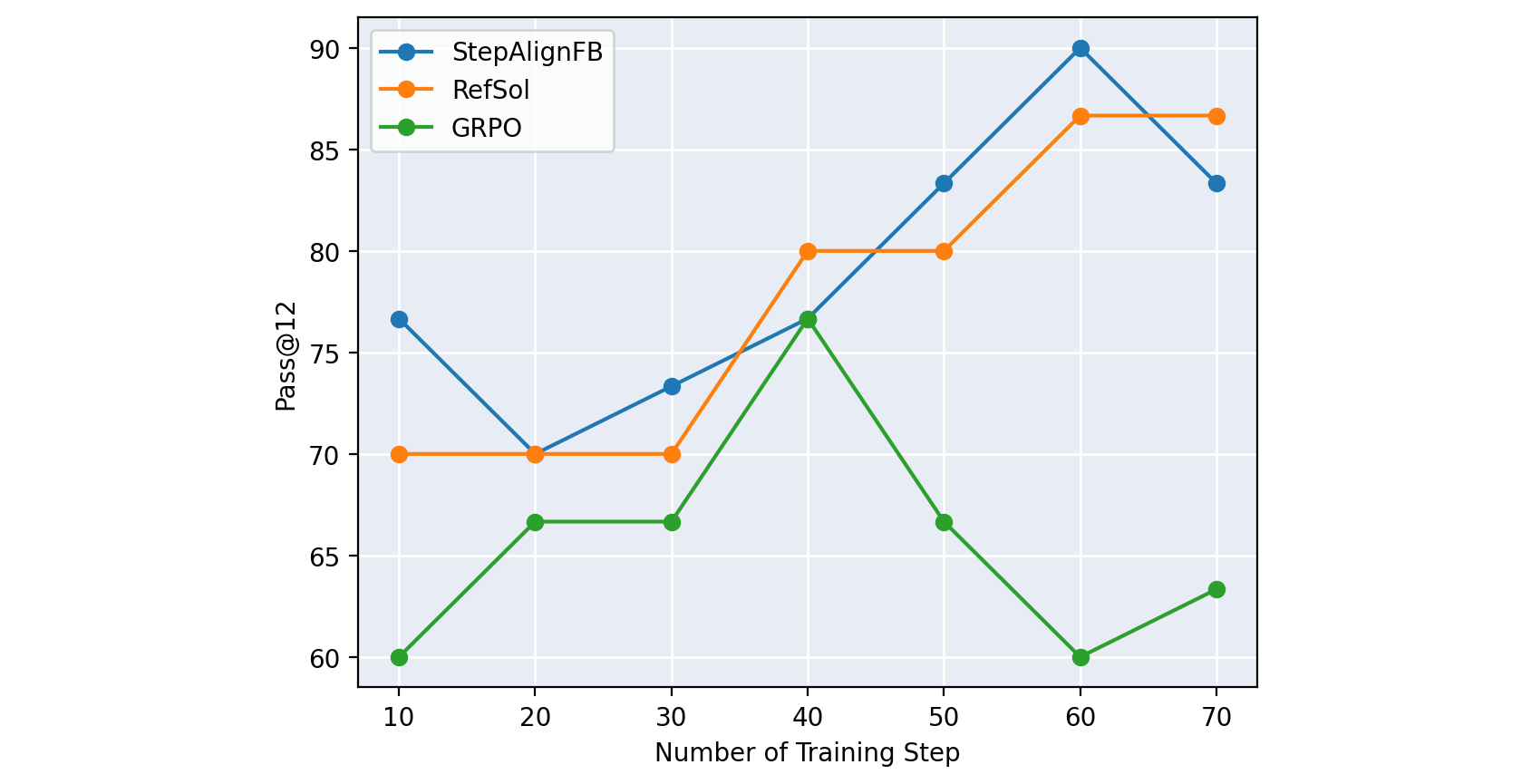
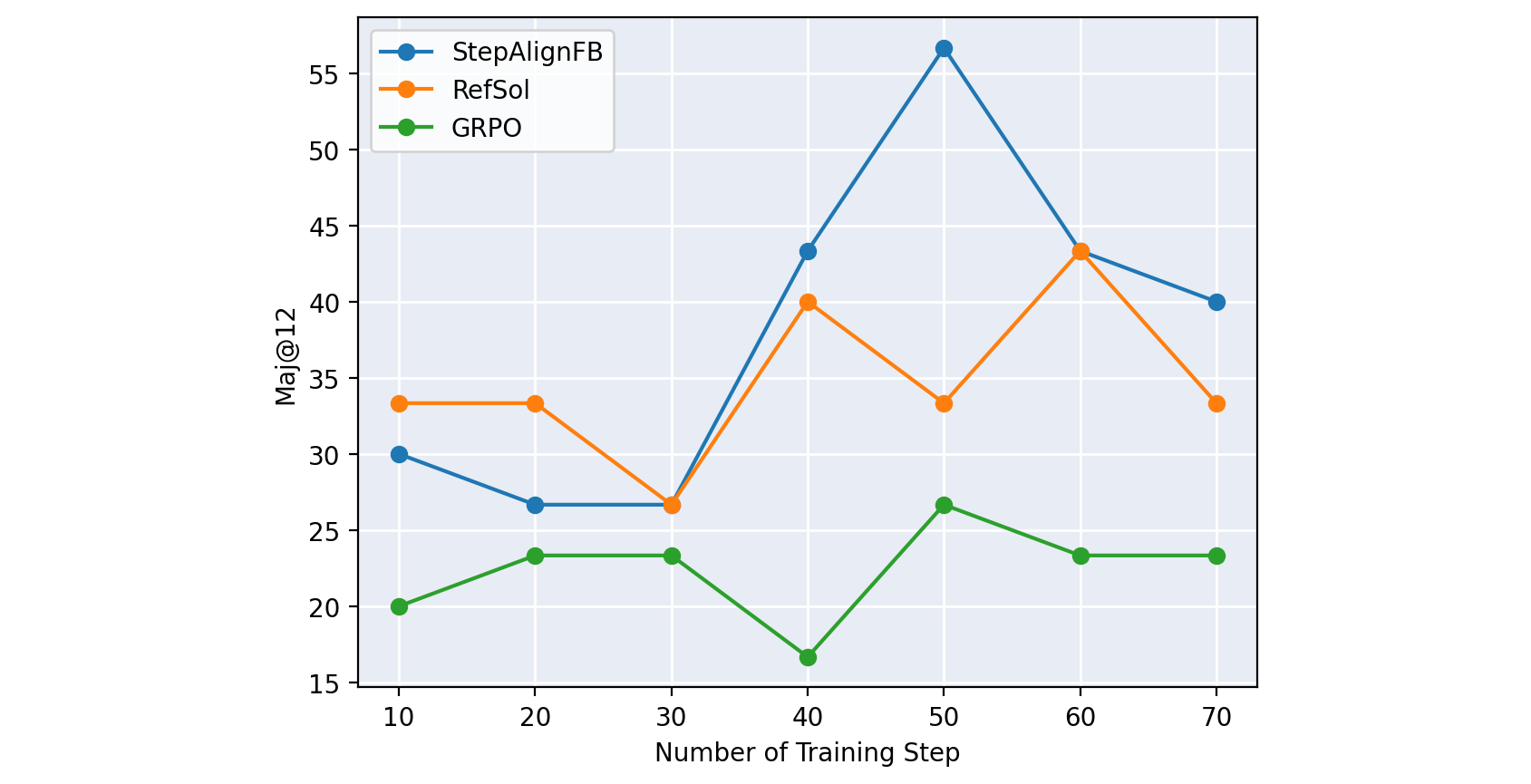
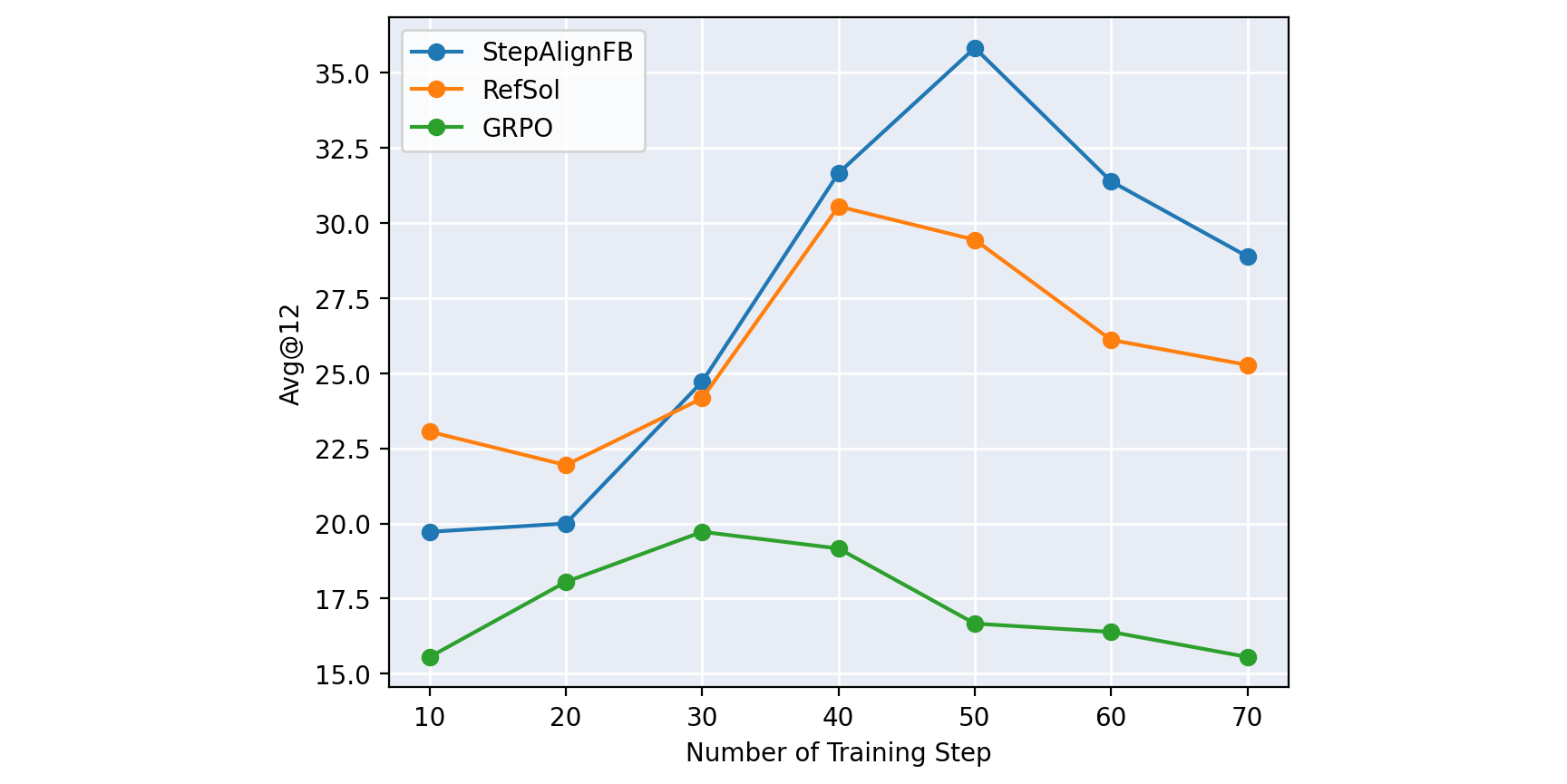
At the per-metric best checkpoints:
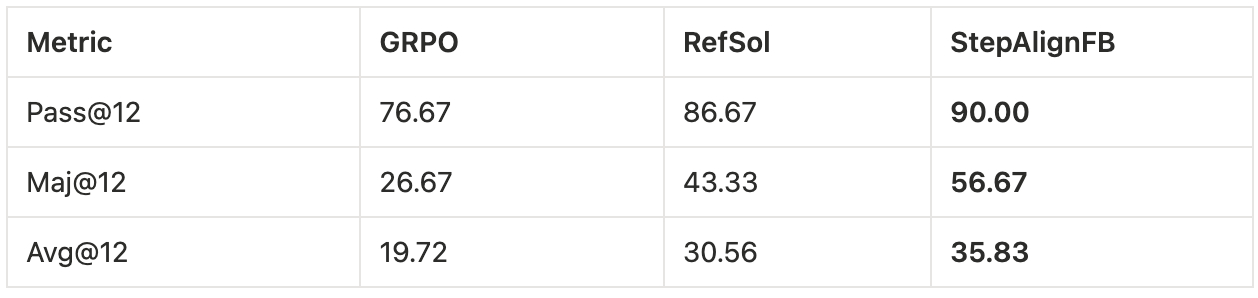
The Avg@12 gaps are large in absolute terms: StepAlignFB beats GRPO by 16 points and RefSol by 5. There is also an interesting pattern across metrics. Pass@12 (which only asks whether any of the 12 samples landed on the right answer) has the smallest gap. Maj@12 and Avg@12 (which measure how much probability mass the model concentrates on correct answers) show the largest gaps, and StepAlignFB pulls ahead most decisively on Maj@12.
Why step-aligned feedback wins: a look at the per-token signal
So why does step-aligned feedback produce a more effective learning signal?
Recall the per-token log-likelihood ratios view from earlier: for any rollout, we can measure how much the feedback shifts the model's distribution at each token. Applying this analysis to RefSol and StepAlignFB on the same solver rollouts illustrates the difference between the two methods.
We walk through three cases.
A fully correct rollout.
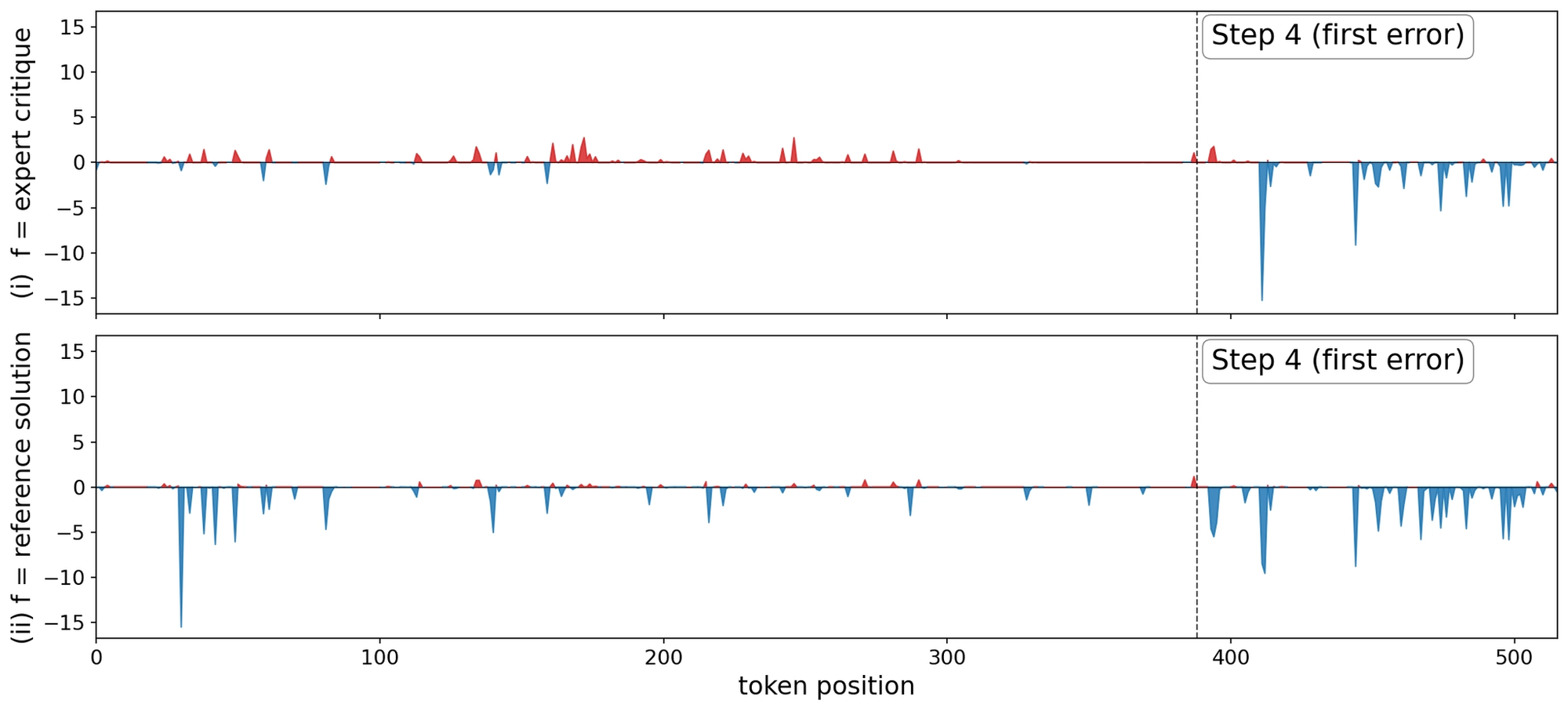
In the first case, the solver reaches the correct answer through valid reasoning. A useful critic should reinforce this throughout. The plots below show per-token log-likelihood ratios under StepAlignFB and RefSol contexts.
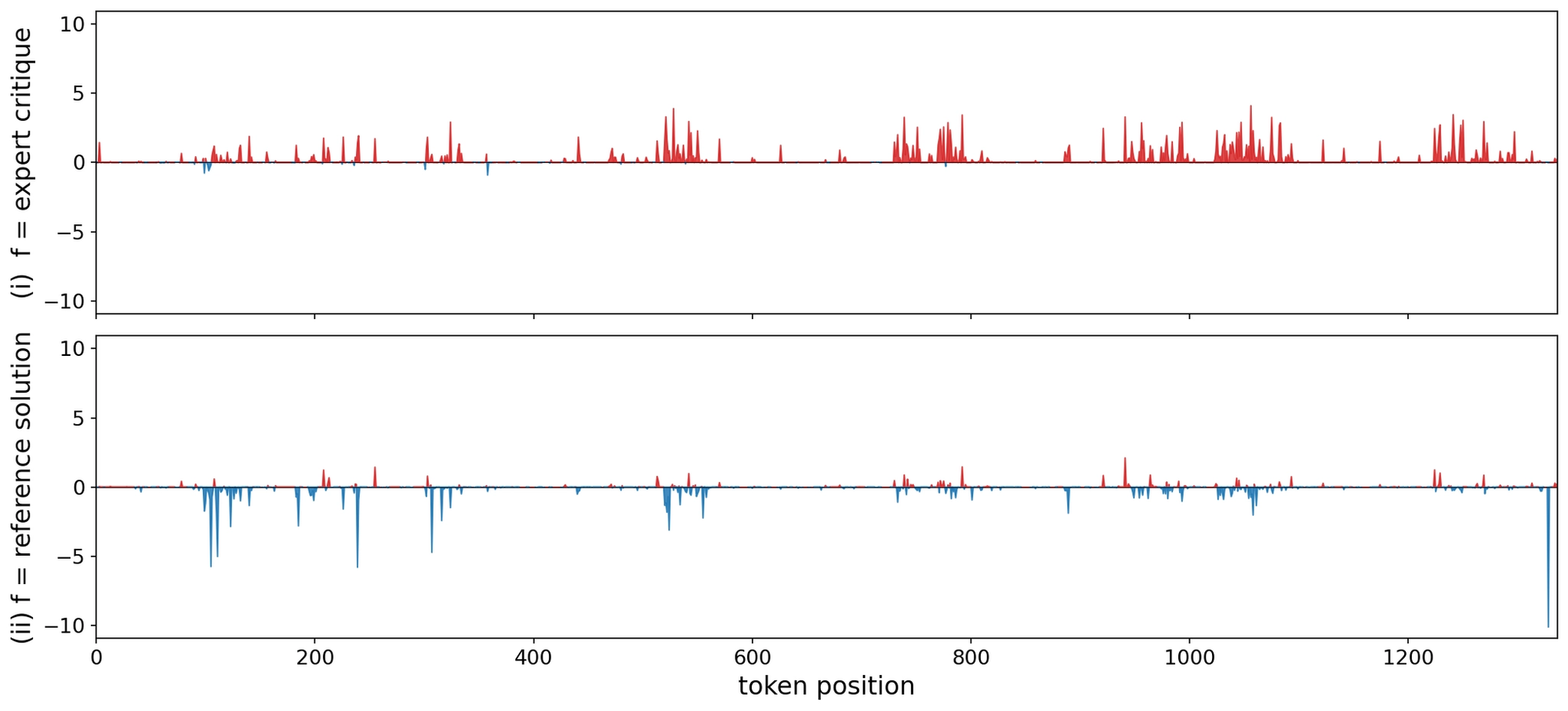
StepAlignFB (top) reinforces the solver's correct reasoning trace. The critic recognizes the rollout as correct and reproduces it almost-verbatim. This results in the original correct behavior to be encouraged. However, RefSol (bottom) produces a diffuse negative signal across the entire rollout, causing the behavior to change.
A rollout with an incorrect step.
In the second case, the solver begins with a valid reasoning trace before making a mistake. An effective critic should reinforce the correct early steps and intervene at the point of error. The plots below show log-likelihood ratios for this case under StepAlignFB and RefSol contexts.
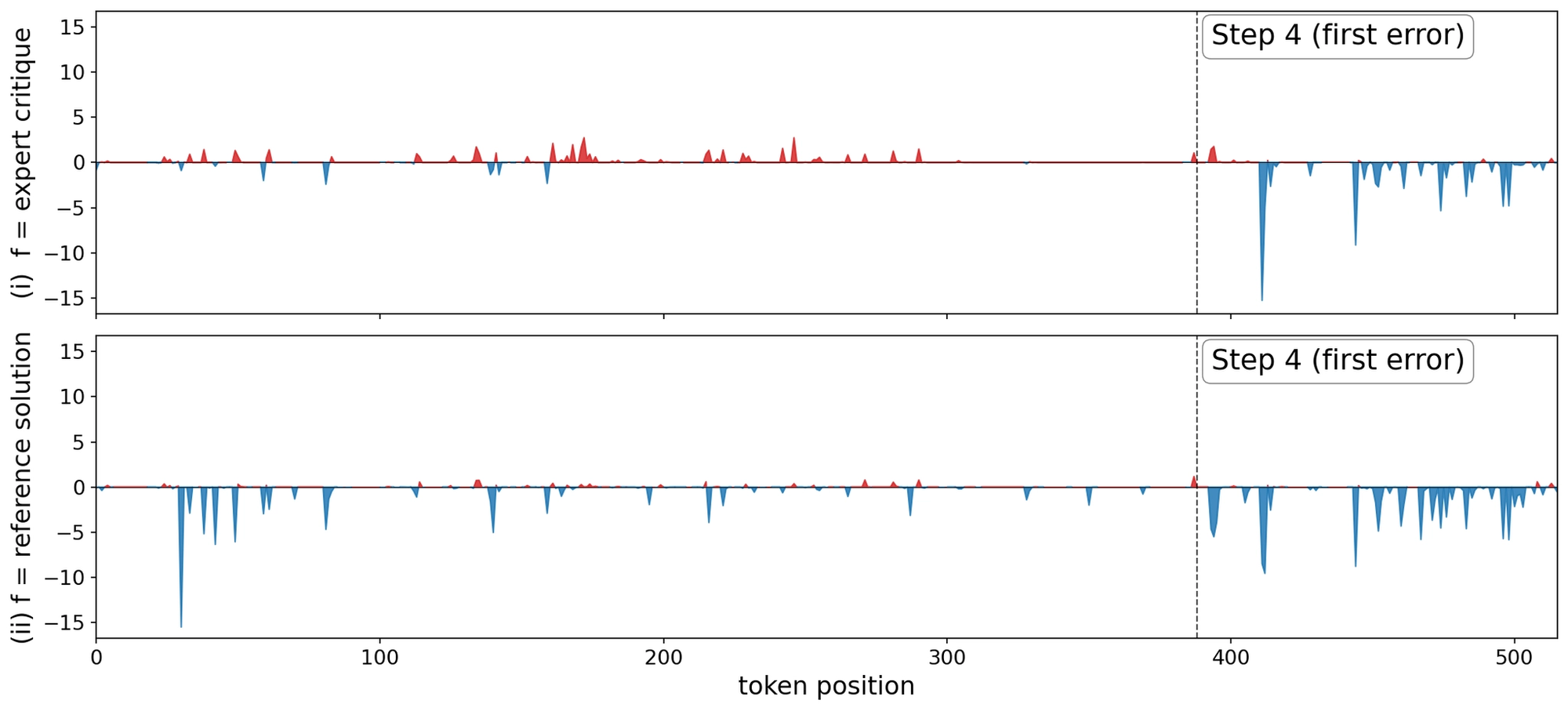
StepAlignFB (top) produces a sharp negative cluster concentrated at the tokens of the erroneous step. In addition, StepAlignFB reinforces the correct reasoning traces prior to the erroneous step. RefSol (bottom) produces a broadly negative likelihood ratio across the entire trace, conflating the error with everywhere the solver’s path diverges from the canonical solution.
A rollout with incorrect approach.
In the third case, the model adopts a wrong approach from the start. It starts enumerating values for the target variable until it exhausts its token budget. With nothing to reinforce, the critic falls back to sharing its own full solution, making StepAlignFB and RefSol very similar. The plots below show the log-likelihood ratios for this case.
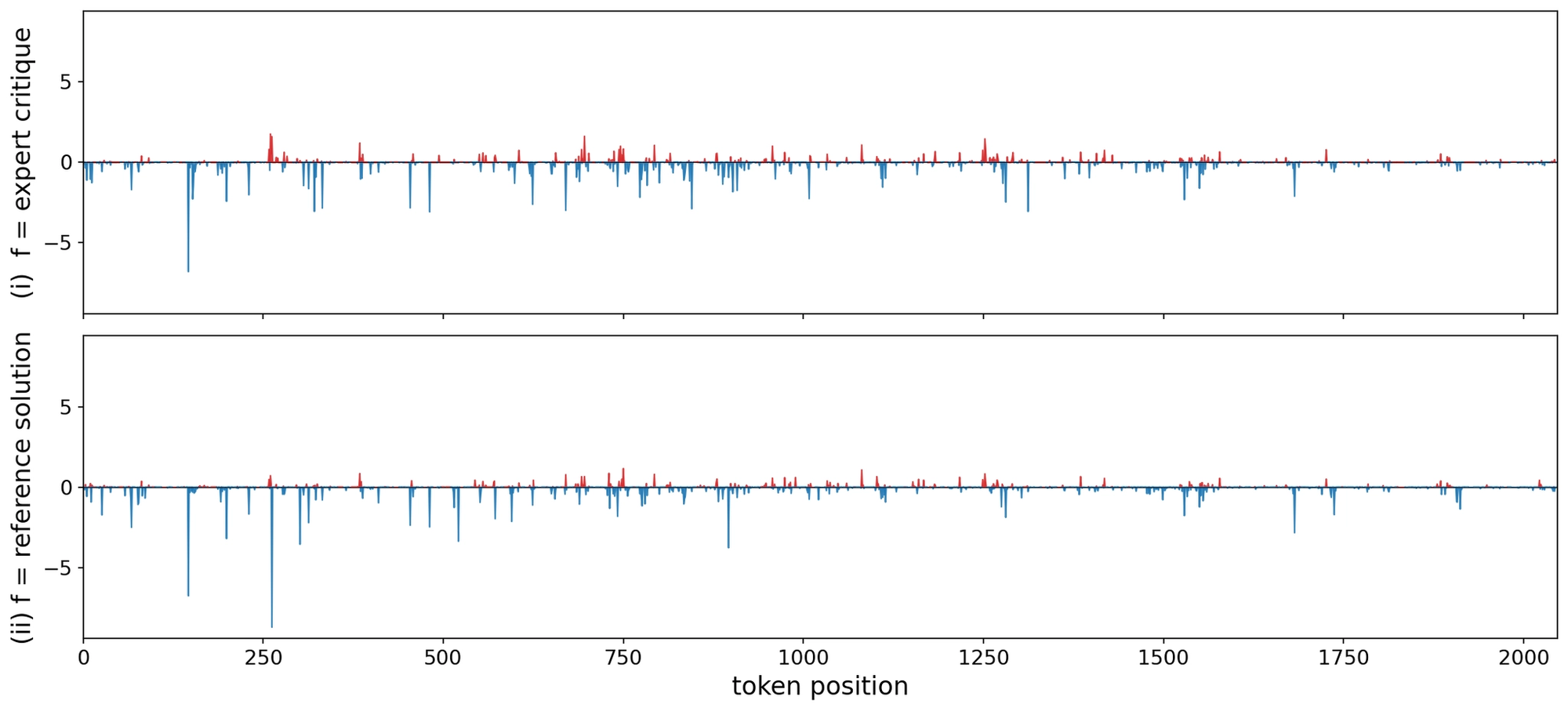
Since the critic responds by producing a complete alternative solution, the update signals from StepAlignFB and RefSol end up similar.
Connection to process supervision
Process supervision scores individual reasoning steps; outcome supervision only scores the final answer. Step-level rewards have been shown to outperform outcome-only rewards for mathematical reasoning [Lightman et al., 2024; Cobbe et al., 2021]. It pinpoints exactly where reasoning breaks down and discourages shortcut paths to correct answers. The drawback is cost: it requires step-labeled data and a separately trained reward model.
Our finding is a distributional generalization: step-aligned textual feedback provides richer-than-scalar process supervision, and the self-distillation mechanism converts it into per-token credit, all without training a reward model. This is visible in Fig. 7 (the per-token log-likelihood ratios for a rollout containing an incorrect step).
Takeaways
We looked into how context affects self-distillation effectiveness - specifically, whether aligning the context with the model's own reasoning trace leads to better learning than simply providing more information.
To test this, we compared three training signals: sparse binary reward (GRPO), reference-solution distillation (RefSol), and step-aligned feedback (StepAlignFB). We showed that how you structure feedback matters a lot. StepAlignFB zeroes in on exactly where the solver goes wrong, essentially acting as implicit process supervision.
However, there is a cost caveat. Generating high-quality step-aligned critiques needs a capable critic model, making StepAlignFB the priciest option. RefSol sits in an interesting middle ground: for large datasets, it also leans on a strong model, but it isn't tied to specific rollouts, so you can reuse it across training runs.
The broader takeaway is that the advantage of self-distillation isn't just access to more context. It is access to context whose structure matches the reasoning trajectory the model needs to correct. Feedback design is an under-explored lever in post-training, and one that sits outside the usual RL-vs-distillation debate. As multi-agent pipelines keep growing and agentic systems become more common, we think this is going to become an increasingly active area of research.
Read the full research paper here: https://arxiv.org/abs/2606.11173