Verde Verification System In Production
In this blog post, we dive into the landscape of verification methods, discuss their advantages and drawbacks, and explain our method, Verde.

In this blog post, we dive into the landscape of verification methods, discuss their advantages and drawbacks, and explain our method, Verde.
Why Verification Matters
Verification of machine learning execution enables both outsourcing compute-intensive tasks to third parties and ensuring transparency in output generation.
- For training or fine-tuning tasks, verification allows clients without sufficient hardware resources to outsource these tasks to third-party compute providers and verify they are performed correctly.
- For inference tasks, verification allows clients who rely on external parties for the output generation to check the correctness of the generated outputs.
Combined with reward and penalty mechanisms, verification enables game-theoretically sound decentralised machine intelligence among untrusted parties.
Background on Verification Methods
Existing verification methods can be classified into three categories: trust-based, learning-based, and execution-based.
In trust-based methods, clients trust the device performing ML execution via TEE (Trusted Execution Environments) such as Intel SGX, or trust the reputation of compute providers. While these mechanisms simplify verification by reducing it to a trust problem, they also inherit its drawbacks. First, TEE is a developing technology and several vulnerabilities have been found in early versions. Second, relying on TEEs reduces device availability since most GPUs lack such capabilities. Finally, reputation-based systems suffer from the bootstrapping problem—reputation can only be built through either additional verification or a referral system that requires trust in the initial set.
In learning-based methods, verification is done by monitoring how the model learns during training. Proof-of-Learning enables verification by logging training checkpoints and later verifying those with large gradient shifts. However, it has been shown to be vulnerable to spoofing attacks. Later, Proof-of-Training-Data was proposed as an improvement over proof-of-learning, where the 'learning' is captured via memorisation. More specifically, verification of a model training relies on how well the model memorises the batches it was trained on. Both learning-based methods are heuristic verification methods that do not guarantee the correctness of the execution, and also fail to detect small-scale data manipulations, such as injecting backdoored data into the training process.
In execution-based methods, verification is done by checking whether the compute provider followed the exact steps of the task. This can be accomplished either through cryptographic proofs using SNARKs or through refereed delegation. SNARK-based proofs allow clients to verify execution correctness with low overhead, but generating such proofs costs orders of magnitude more than the task itself. For this reason, we use refereed delegation, where the task is assigned to two (or more) compute providers. Assuming at least one is honest, a referee or client can efficiently verify execution correctness.
Refereed Delegation
The core idea of refereed delegation is that if two compute providers disagree on an ML execution, a referee can determine which provider is honest by executing a single operation rather than running the entire task. Assuming the task is agreed upon as a sequence of ordered operations, if there is disagreement in the final result, the referee can run a bisection game to pinpoint the first operation where they disagree. The bisection game functions as a binary search on these ordered operations to determine where the first disagreement occurred. Once it is found, the referee can run that operation to determine which provider is honest or malicious accordingly.
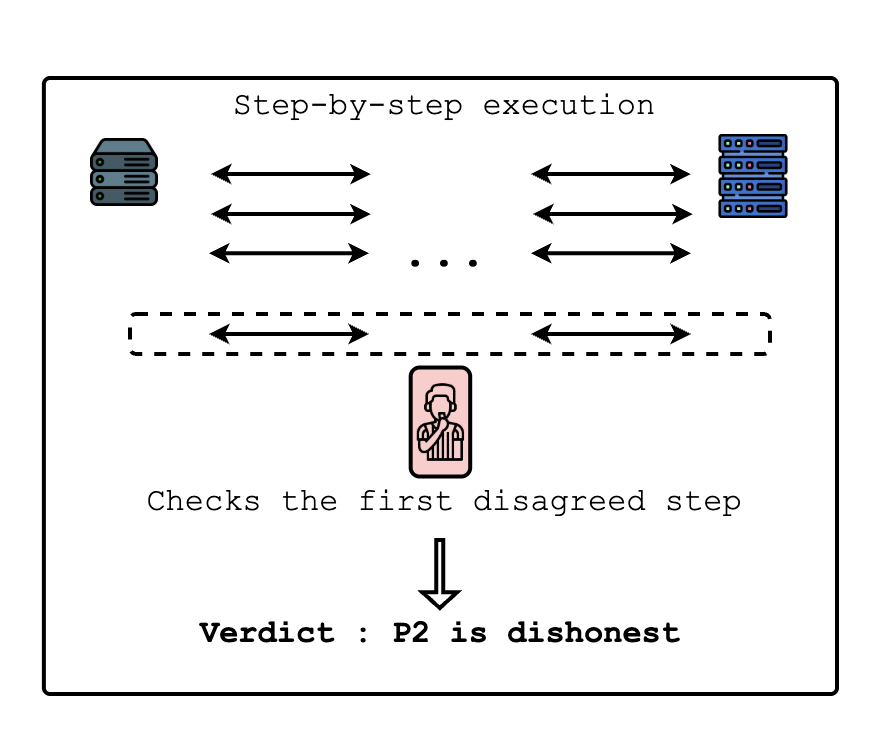
Thanks to its efficient dispute mechanism, refereed delegation has already been used in blockchain systems, such as optimistic rollups, where the chain itself acts as the referee. However, adapting refereed delegation to ML execution presents several challenges: pinpointing disagreements in an ML compute graph; the failure of naive re-execution due to non-associative floating point operations; and repetitive training steps that can explode task size when represented as a sequence of ordered operations.
Agatha addresses the first challenge by converting ML inference tasks into topologically sorted compute graphs that allow pinpointing disagreements. Regarding non-associativity challenge, it uses fixed-point operations. Later, Toploc uses locality-sensitive hashing to allow verification in the presence of small divergences in floating point operations. However, both methods do not extend to training tasks, as fixed points significantly limit the range of representable values, and the hashing method would fail in training since the differences caused by non-associativity would propagate into significant deviations.
Verde
Verde utilizes RepOps and a two-level bisection game to achieve refereed delegation for training and fine-tuning tasks in addition to inference.
RepOps (reproducible operators) enforces a fixed ordering of operations for common ML operators (such as matrix multiplication) to overcome the non-associativity problem. With RepOps, we achieve bitwise-reproducible results across diverse hardware. RepOps is a standalone contribution that enables reproducibility of scientific and industrial results by third parties, among many other use cases.
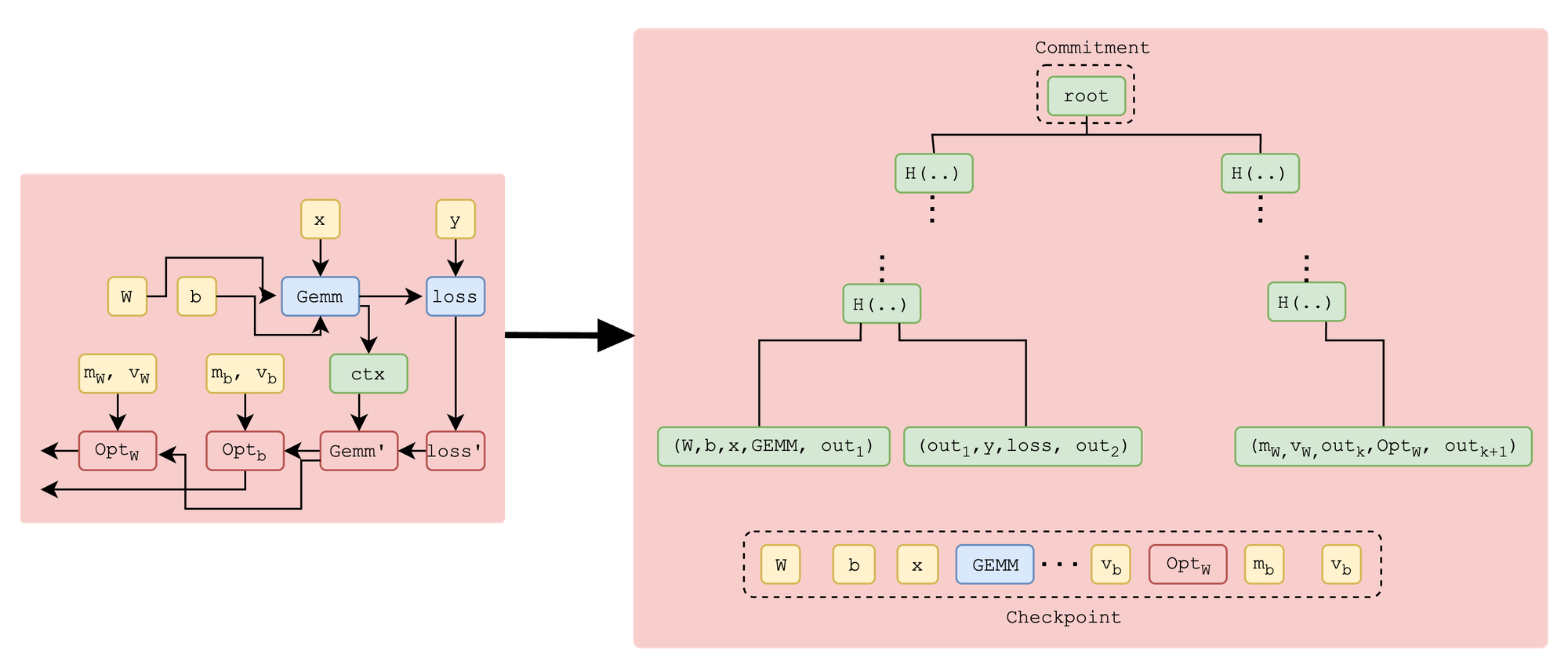
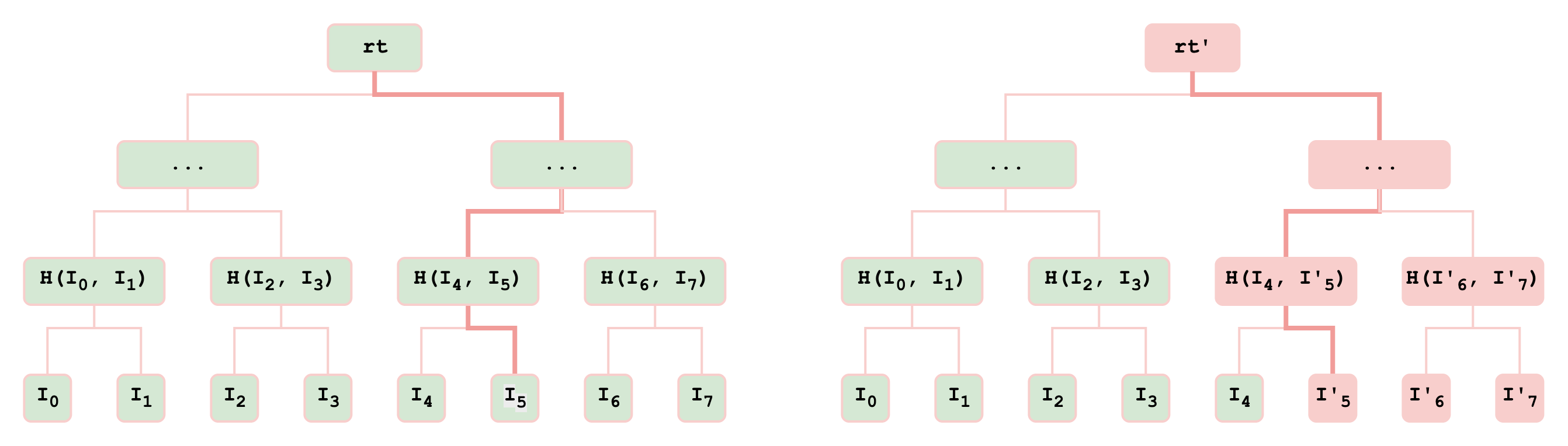
The two-level bisection game allows us to efficiently pinpoint disagreements at two levels: first at the iteration level, then at the operation level. To achieve this, compute providers commit to each training iteration (represented as a compute graph) via a Merkle tree where each node is a tuple of (inputs, operator, output) for the corresponding operator in the compute graph. In Figure 2, we illustrate a simple compute graph converted into a commitment. Later, each iteration commitment is combined into higher-level Merkle tree, as shown in Figure 3. Using the bisection game, at the higher level, we first pinpoint the first iteration where the providers disagree (iteration 5 in the example), then, within that iteration, we pinpoint the first disagreed operation. Finally, the referee executes that operation to determine which provider is honest.
How it works
Here, we describe the high-level steps of verifying an ML execution, which can be training, fine-tuning, or inference tasks.
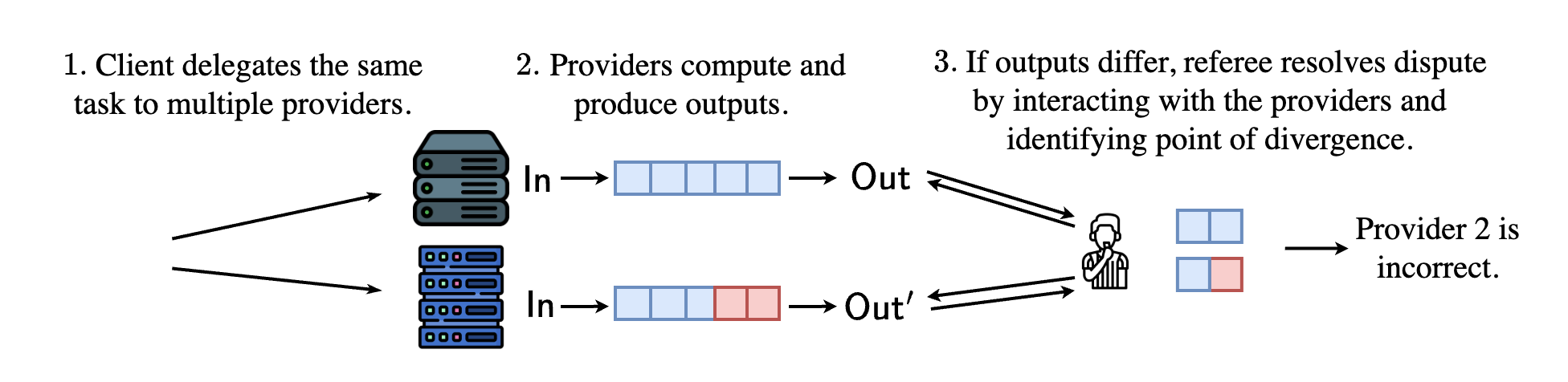
- Initially, two compute providers are assigned to the task
- First, both compute providers agree on the setup: compute graph, training data, etc.
- They execute the task via RepOps and share their outputs.
- If the outputs differ, arbitration starts. Two-level bisection game pinpoints the first disagreed operation.
- The referee delivers a verdict on the correct outcomea. The referee executes the operation to determine which output is correct.
Verde in Judge
Verde and RepOps are already deployed in Judge.
- Verde ensures an open and transparent prediction market that enables verification of evaluations.
- RepOps allow verification to be conducted across diverse hardware.
Extensions to Verde
Because of refereed delegation, Verde requires running the same task by multiple parties. However, this overhead can be significantly reduced for both training and inference tasks.
Single-Step Inference Verification
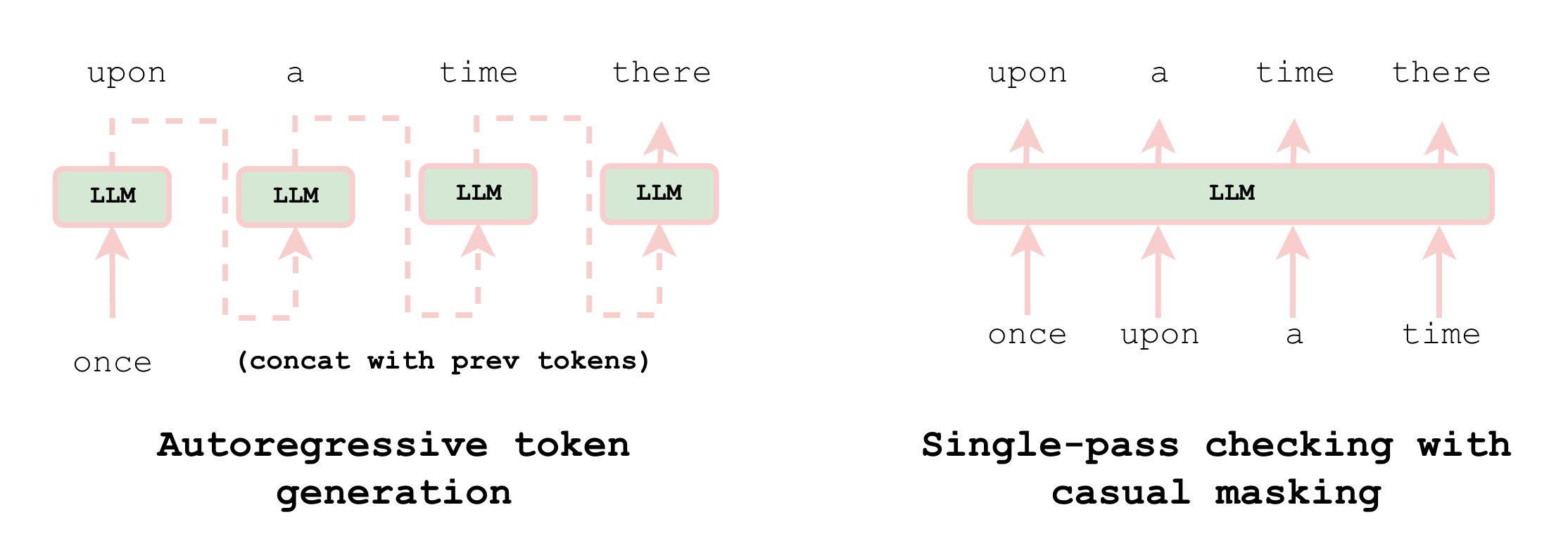
Common LLMs are autoregressive models where each token generation is done through a single forward pass, which is then concatenated with the input for the next token generation. Similar to the teacher forcing method, autoregressive token generation allows verification of generated tokens in a single forward pass (via causal masking)—the same technique used in speculative decoding. This reduces the overhead of verifying an inference task to a single forward pass.
Partial Re-execution Training Verification
In naive verification of a training task (the same applies to fine-tuning), two compute providers are assigned to execute the entire task simultaneously. However, one compute provider (the trainer) can execute the entire training while an additional provider (the verifier) checks the task through partial re-execution.
The trainer commits and stores several checkpoints during training. Later, a randomly selected checkpoint can be replicated by the verifier using the same verification method. The only difference is that the verifier re-executes only a single checkpoint interval (randomly selected by the chain) rather than the entire task. Combined with a reward and penalty mechanism where the penalty for malicious behavior far exceeds the reward for completing the task, this ensures that a rational trainer behaves honestly even when only a portion of the task is verified.
FAQs
Q: What problem does Verde solve?
Verde makes it possible to trust machine learning results produced by others when you don't control their hardware. It does this by comparing two independent runs of a single task and letting a referee verify only the single operation where they disagree, instead of re-running the entire job.
Q: Does Verde detect hallucinations generated by a model?
No, Verde ensures that the output is indeed generated by the corresponding model via using the exact model weights and the input prompt. In other words, Verde allows you to check whether the output of the model is manipulated or not.
Q: Does Verde guarantee that a model's output is correct?
Not exactly. Verde guarantees that the output was faithfully produced by the declared model and data, not that the model itself is correct. Think of it like a verifiable signature on a check—the signature doesn't guarantee the check will clear or that the account is active, but it does confirm the signature came from the signer.
Q: What role does RepOps play in Verde?
RepOps (Reproducible Operators) ensures that the same ML operation produces identical bitwise results, regardless of GPU or environment. Without this, even honest nodes could disagree due to small numerical differences.
Q: Where is Verde being used today?
Verde powers verification inside Judge. It makes sure the model judgements can be independently verified.
Read the full research paper here:
https://arxiv.org/abs/2502.19405