F-TIS: Heterogeneous GRPO Without Homogeneous Assumptions
Our method, F-TIS, enables diverse models to collaborate in decentralised GRPO by combining truncated importance sampling with filtering. Across model-size, expertise, and PEFT heterogeneity, F-TIS matches on-policy convergence and, in some cases, improves out-of-distribution reasoning.

GRPO is a commonly used tool for reasoning-focused LLM post-training. It trains by sampling multiple completions per prompt, rewarding them, and updating toward the relatively better completions. Here, each prompt needs several autoregressive completions, and distributed GRPO systems speed up the generation by parallelising the completions among workers which run the same model. That assumption allows on-policy training, yet limits its applicability in a decentralised setting where participants may bring different hardware, model sizes, model specialisations, or trainable parameter budgets.
Our paper ‘F-TIS: Harnessing Diverse Models in Collaborative GRPO’ introduces, F-TIS (Filtered Truncated Importance Sampling), a GRPO-style training method that allows heterogeneous models to collaborate in the same RL run. Instead of synchronising gradients or weights, nodes only share generated tokens and per-token log-probabilities, giving a communication cost of roughly 8 bytes per token in our setup. Across the evaluated heterogeneous settings, F-TIS reaches nearly identical final convergence to on-policy training and in some cases improves out-of-distribution performance by up to 12%.
The Problem: Heterogeneity Makes GRPO Off-Policy
GRPO assumes that the policy learning from a completion is close to the policy that generated it. For a prompt \(p\), a generator policy \(\pi_{\theta_{\text{gen}}}\) samples a group of completions \(a_i\). Each completion receives reward \(r_i\), and GRPO forms a group-relative advantage\[\hat{A}_i = \frac{r_i - \mu_r}{\sigma_r}.\]The policy update then depends on the likelihood ratio between the learner and the generator,\[\frac{\pi_\theta(a_{i,t} \mid p \circ a_{i,<t})}
{\pi_{\theta_{\text{gen}}}(a_{i,t} \mid p \circ a_{i,<t})}.\]
In homogeneous distributed GRPO, this ratio is expected to stay close to one because all workers generate from nearly the same policy. In decentralised training, this assumption breaks. Models may differ in size, expertise, or trainable parameters; even models initialised identically can drift apart if they only exchange completions. Once the generator and learner diverge, shared completions become off-policy samples. This matters because off-policy samples can turn the GRPO update into destructive noise. A completion produced by a smaller model may be unlikely under a larger model; or a coder-specialized model may generate traces that a base model would not naturally produce. Treating all of these completions as if they came from the learner can push the policy in the wrong direction.
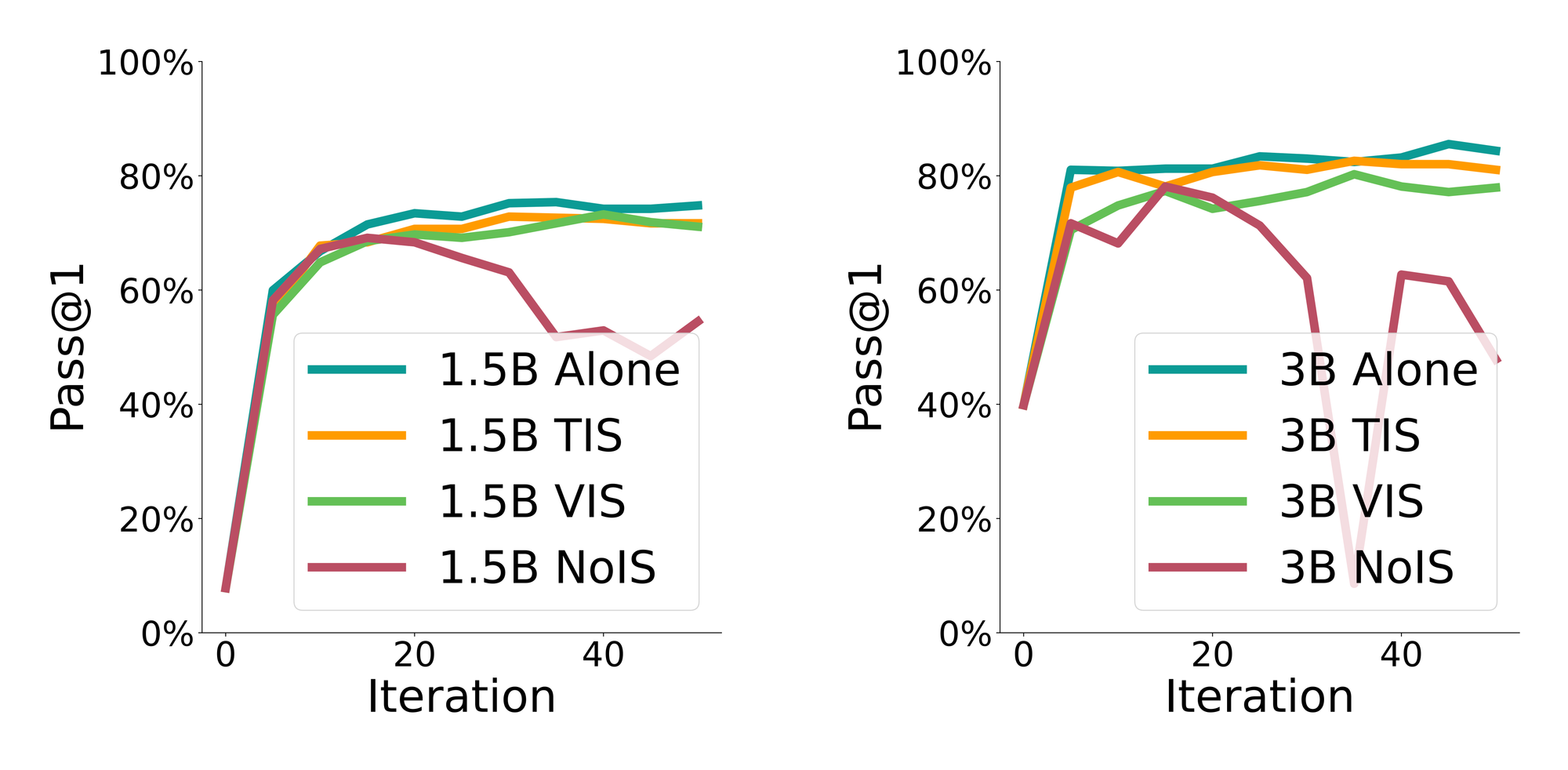
We evaluate this directly with Qwen2.5-1.5B and Qwen2.5-3B trained together on GSM8k. NoIS, which uses no importance sampling, performs significantly worse than training each model alone. Existing off-policy corrections improve performance: VIS (vanilla importance sampling) communicates generator log-probabilities and applies importance sampling, while TIS (truncated importance sampling) truncates the importance correction to prevent extreme ratios from dominating the update. In our experiments, VIS and TIS behave similarly for the smaller model, but TIS is clearly better for the larger model, motivating it as the base of F-TIS.
The Idea: Filtered Truncated Importance Sampling
F-TIS combines the stability of filtering with the correction provided by TIS. TIS handles the generator–learner mismatch by correcting for the probability of a sampled token under both policies, while capping the correction with a constant. Filtering then decides which off-policy samples should actually contribute to the update. The filtered advantage is
\[\hat{A}_{t,i} =
\begin{cases}
\hat{A}_i & \text{if } \hat{A}_i > 0 \text{ or } D_{KL}(\pi_\theta \| \pi_{\theta_{\text{gen}}}) < g \\
0 & \text{otherwise}.
\end{cases}\] The intuition is simple: A positive-advantage off-policy completion can still teach the learner what to move toward, a negative-advantage sample that is close to the learner can still teach it what to avoid, but a negative-advantage sample far from the learner often gives a bad signal: it pushes the model away from behavior it was unlikely to produce in the first place.
Results
In our experiments, unless otherwise specified, we use GSM8k for training, evaluate validation pass@1 with greedy decoding, and test final models on MATH-500 as an out-of-distribution reasoning benchmark. In our experiments, we train pairs of Qwen2.5-1.5B, Qwen2.5-3B, Qwen2.5-Coder-1.5B, and Qwen2.5-Coder-3B models depending on the tested heterogeneity. We evaluate F-TIS across three heterogeneity settings: model size differences, such as Qwen2.5-1.5B trained with Qwen2.5-3B; model expertise differences, such as Qwen2.5 trained with Qwen2.5-Coder at the same scale; and trainable-parameter differences, where a fully fine-tuned model trains with a LoRA/PEFT version of the same base model.
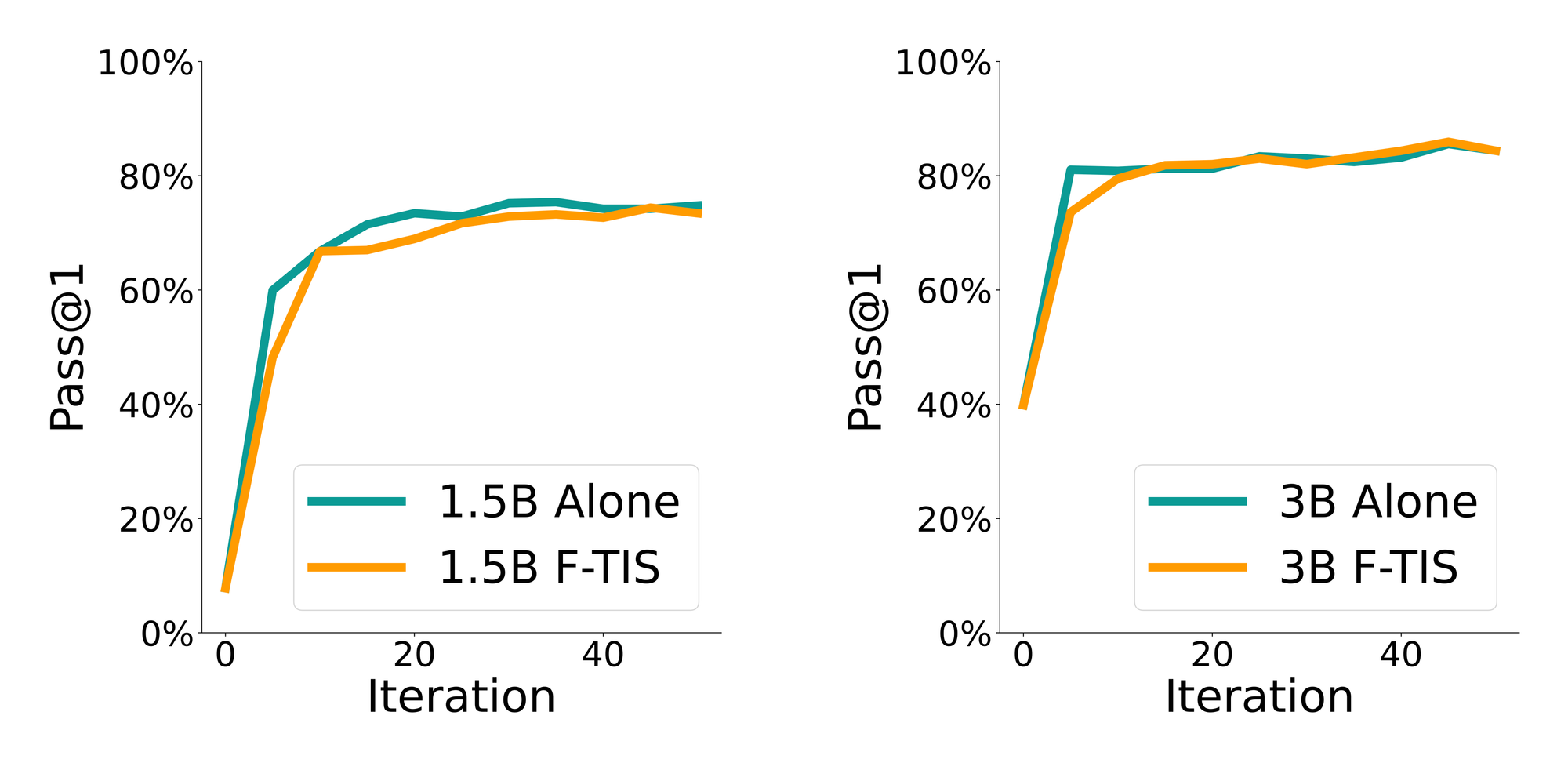
For model size heterogeneity, we train Qwen2.5-1.5B with Qwen2.5-3B, and Qwen2.5-Coder-1.5B with Qwen2.5-Coder-3B. In both settings, F-TIS reaches near-identical final validation performance to training each model alone. The main difference is convergence speed: collaborative training is initially slower, but catches up by the end of training. Moreover, we observe substantial improvements in smaller models with out-of-distribution evaluations.
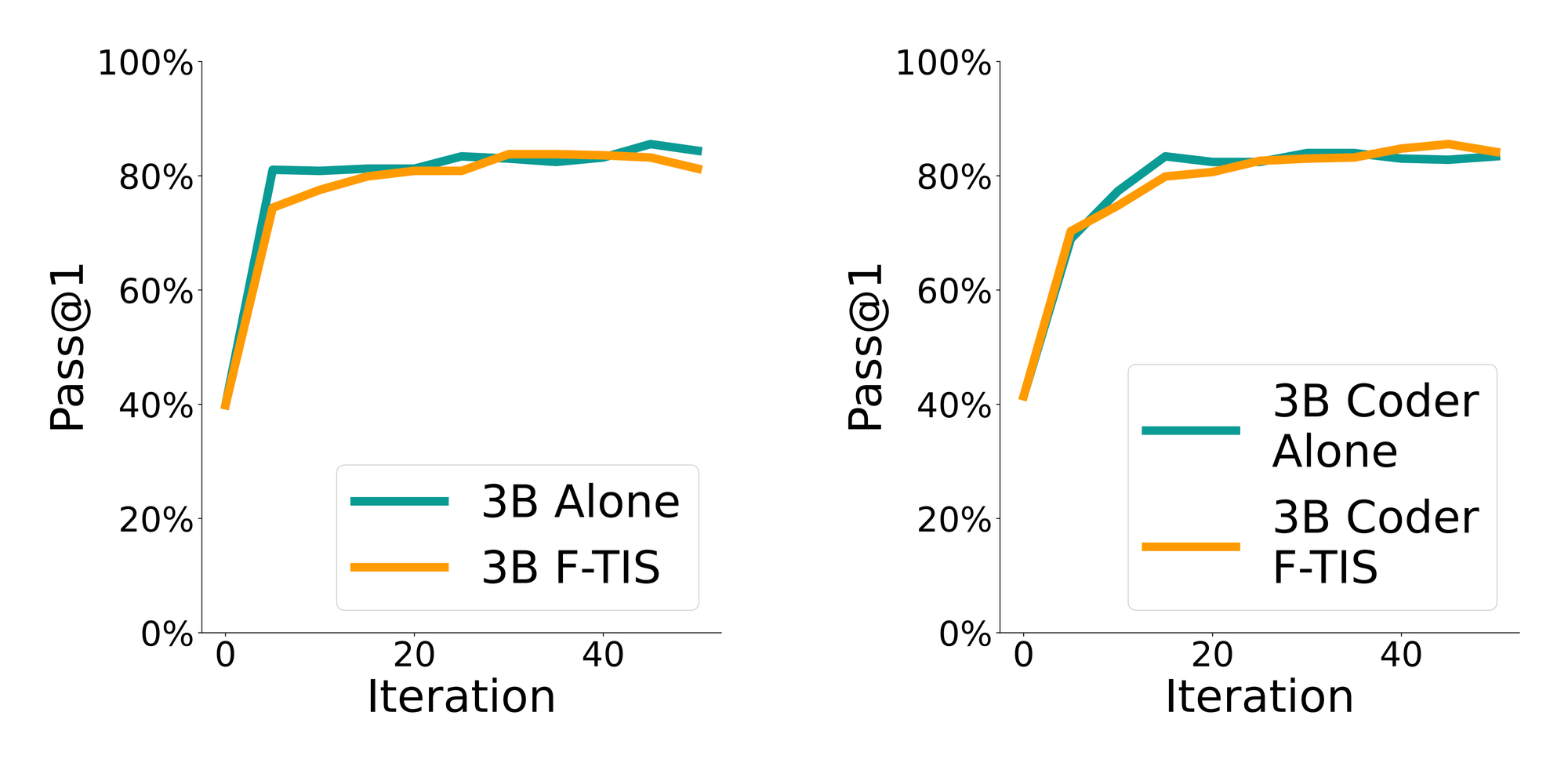
For model expertise heterogeneity, we pair models of the same size but different specialisation: Qwen2.5 with Qwen2.5-Coder at both 1.5B and 3B scales. The validation curves show that F-TIS remains stable even when collaborators have different expertise and parameterisations. This is important for decentralised training, where users may bring personalised or specialised models rather than identical checkpoints.
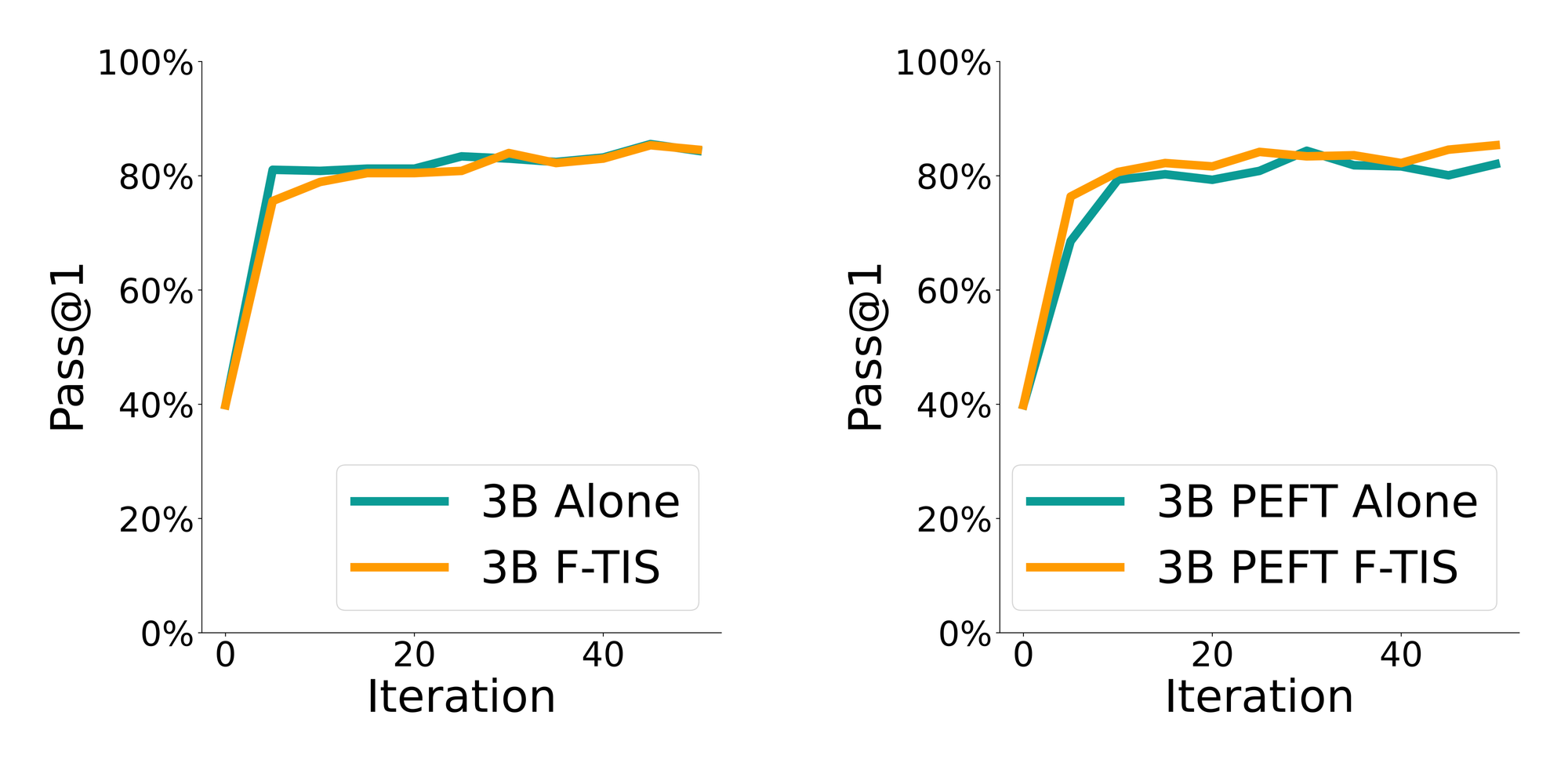
For trainable-parameter heterogeneity, we pair full fine-tuning with LoRA training on the same base model. Here, the most notable result is the 3B LoRA model: when trained collaboratively with the full model, it shows much better convergence than when trained alone. This is also reflected in the out-of-distribution evaluation, supporting the idea that PEFT-based GRPO can improve by using off-policy samples from a non-PEFT model.
Out-of-distribution. On MATH-500, we observe a broader transfer pattern. Across collaborations, the model that performs worse in the alone baseline often improves through joint training, while the stronger baseline model can lose some out-of-distribution performance. The clearest PEFT gain is the 3B PEFT model, which improves from 0.50 to 0.56. A notable exception to the stronger model's drop is the 3B Coder model: it improves from 0.48 to 0.53 when paired with the 3B Base model, and to 0.59 when paired with the smaller Coder model. We attribute this to possible overfitting of the larger Coder model to coding tasks, which may reduce its standalone math reasoning ability and make collaboration especially useful.
Why It Matters
F-TIS makes decentralised GRPO more realistic. Participants no longer need to run identical models or train the same parameter subsets to contribute useful RL experience. Small models, large models, specialist models, and PEFT-trained models can participate in one shared training loop while communicating only lightweight completion data.
The broader point is that, with the right off-policy correction and filtering, heterogeneous models can train together without sacrificing final convergence.
Takeaways
F-TIS shows that naive heterogeneous GRPO fails because shared samples become off-policy, but those samples are not useless. Truncated importance sampling corrects the generator–learner mismatch, while filtering removes the most harmful negative off-policy updates.
Across model size, expertise, and trainable-parameter heterogeneity, F-TIS matches on-policy final convergence in our experiments and can improve out-of-distribution reasoning for weaker or more specialised collaborators.
Read the full research paper here: https://arxiv.org/abs/2605.22537