Stop Multitask Training. Just DUME.
Dynamic Upcycling MoE (DUME) cleverly reuses dense experts trained on different domains to create a unified MoE multidomain expert model. DUME retains the knowledge of the original dense experts without any additional training, offering a cost-effective, scalable solution with no compromises.

In this blog post, we introduce DUME, our training-free method for upcycling domain-expert language models into a single, multidomain Mixture-of-Experts model.
Why care about having a single, multi-domain expert model
Suppose you want a system capable of accurately answering questions in Physics, History, Coding, and Mathematics. You have one distinct expert model per domain; all models share the same architecture, but they do not perform well outside their respective specializations. What is the best strategy to leverage these models to maximize overall performance across each domain while keeping costs low? Figure 1 shows a representation of this scenario.
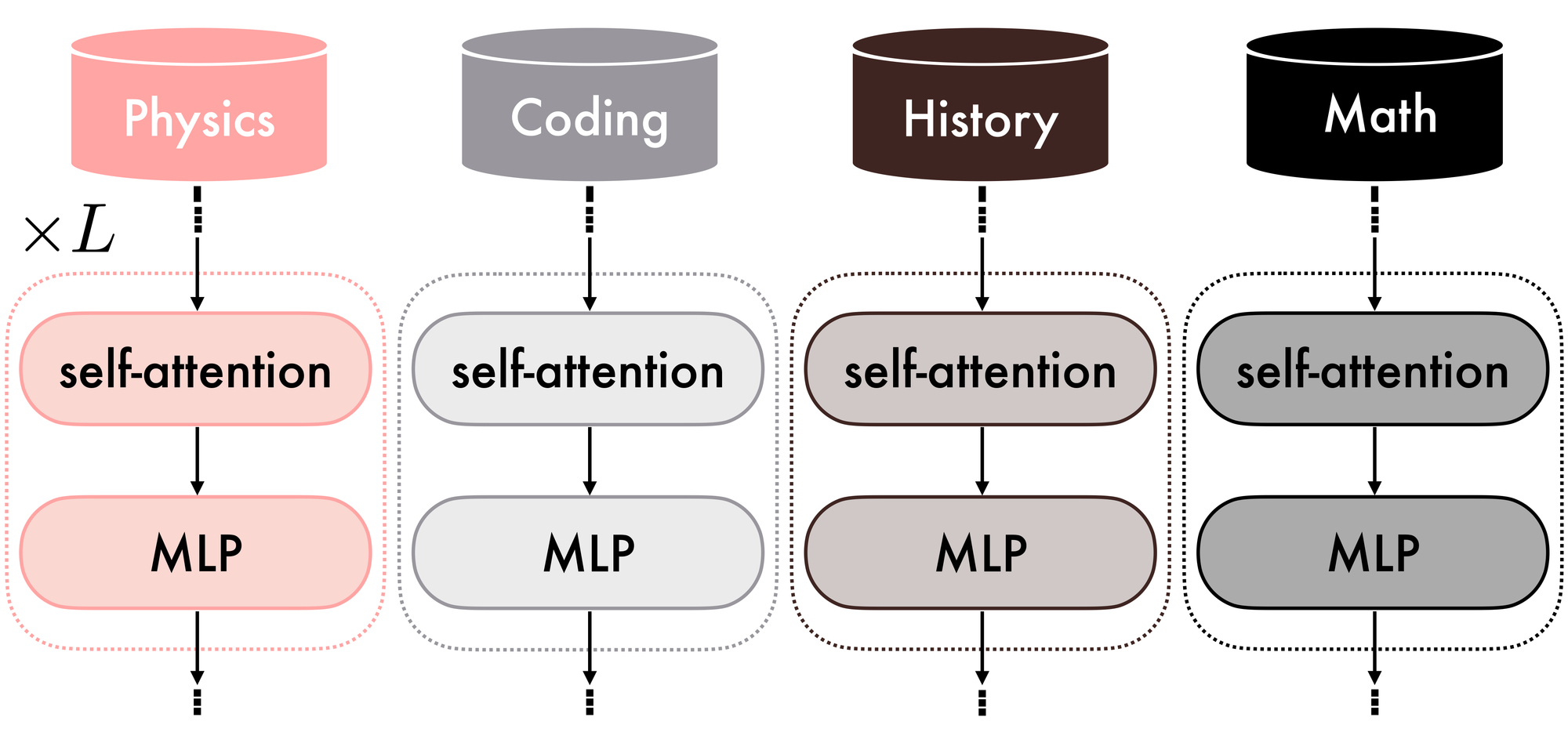
If you attempt to use them directly for inference, several challenges arise:
- Memory constraints. All four models must be loaded simultaneously, quickly depleting memory and computing resources. Even with reduced precision, scaling to many domain experts becomes inefficient. Similarly, ensemble methods also increase latency and cost, as each query must be processed by multiple models and their outputs combined. This makes it challenging to maintain high performance across different domains without a more efficient mechanism for routing or selecting models.
- Model loading overhead. An alternative is to load models into GPU memory only when needed. While this reduces peak memory usage, it introduces significant latency due to repeated data transfers between CPU and GPU memory, resulting in slower inference.
- Expert routing and multidomain capabilities. During inference, you would need to determine precisely which expert model is best suited for each query. Automatically making this decision can be challenging, and without a dynamic routing mechanism, you might be forced to manually select the expert for each question — an inefficient and error-prone approach. Moreover, if you need your system to solve the Schrödinger equation for the hydrogen atom to derive its quantized energy levels, you may need highly specialized mathematical capabilities as well as physics expertise. However, you are only selecting one expert for each query.
Takeaway 1: Deploying a separate model for each area of expertise is impractical, as it leads to high resource demands and complex management challenges.
Having access to a single multidomain expert with strong capabilities across all four domains would inherently address, or even eliminate, all the problems mentioned above. Can we effectively combine our experts to achieve this objective? A possible solution is model merging, in which domain experts are aggregated into the parameter space, typically via arithmetic operations.
Merging models is a challenging option
While appealing, model merging methods are prone to destructive interference: the knowledge or capabilities of individual experts may be lost because their parameters were optimized for different objectives and are incompatible with merging.
Figure 2 shows the average normalized performance across the Math, Multilingual, Coding, and Instruction following domains. The pink bars correspond to the domain experts (e.g., the first bar represents the Math expert, whose score is the average normalized performance across all four domains). The final bar shows the average normalized performance of the model obtained by merging the four experts with task arithmetic. As shown, the merged model performs worse than two of the four individual experts, likely due to destructive interference.
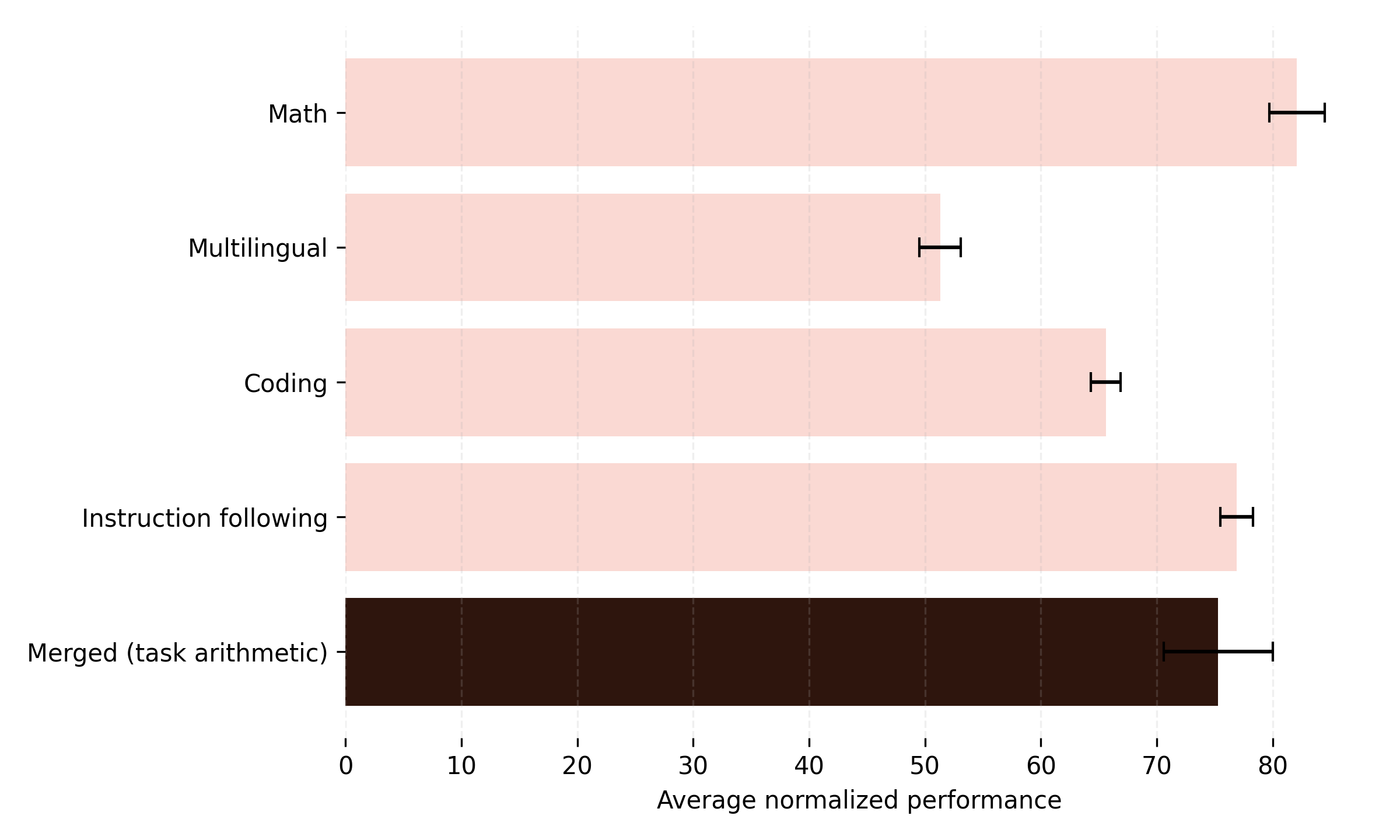
Approaches such as task arithmetic and more structured merging methods attempt to mitigate destructive interference by aligning or selectively combining parameters, but they still often struggle to fully preserve domain-specific capabilities and can degrade performance on individual tasks.
Takeaway 2: Model merging offers an easy-to-deploy, unified multi-domain expert, but achieving strong performance remains difficult due to destructive interference during the merging process.
Multitask training: a heavy hammer
Alternatively, if you have the necessary resources, you might consider multitask training, where a single model is trained to handle multiple domains or tasks simultaneously. In practice, however, this approach is quite challenging:
- One major issue regards optimization difficulties: learning across heterogeneous tasks can lead to negative transfer, where improving performance on one task degrades performance on another, or catastrophic forgetting, where knowledge acquired earlier is lost as new tasks are learned.
- Moreover, data-related challenges arise in decentralized or collaborative settings: aggregating multi-domain datasets can create significant communication overhead and raise privacy concerns, especially when sensitive or proprietary data is involved.
These factors make multitask training a powerful but complex solution that requires careful planning and infrastructure.
Takeaway 3: Multitask training is a traditional method for constructing a multidomain expert. However, it poses significant challenges, including optimization difficulties and data management issues, making it a powerful yet challenging approach.
Model MoErging is the solution you are looking for
At this point, we can refine our question:
Can we find a method that combines expert models from different domains into a single multi-domain expert without costly multitask training, while preserving each expert's knowledge and preventing destructive interference?
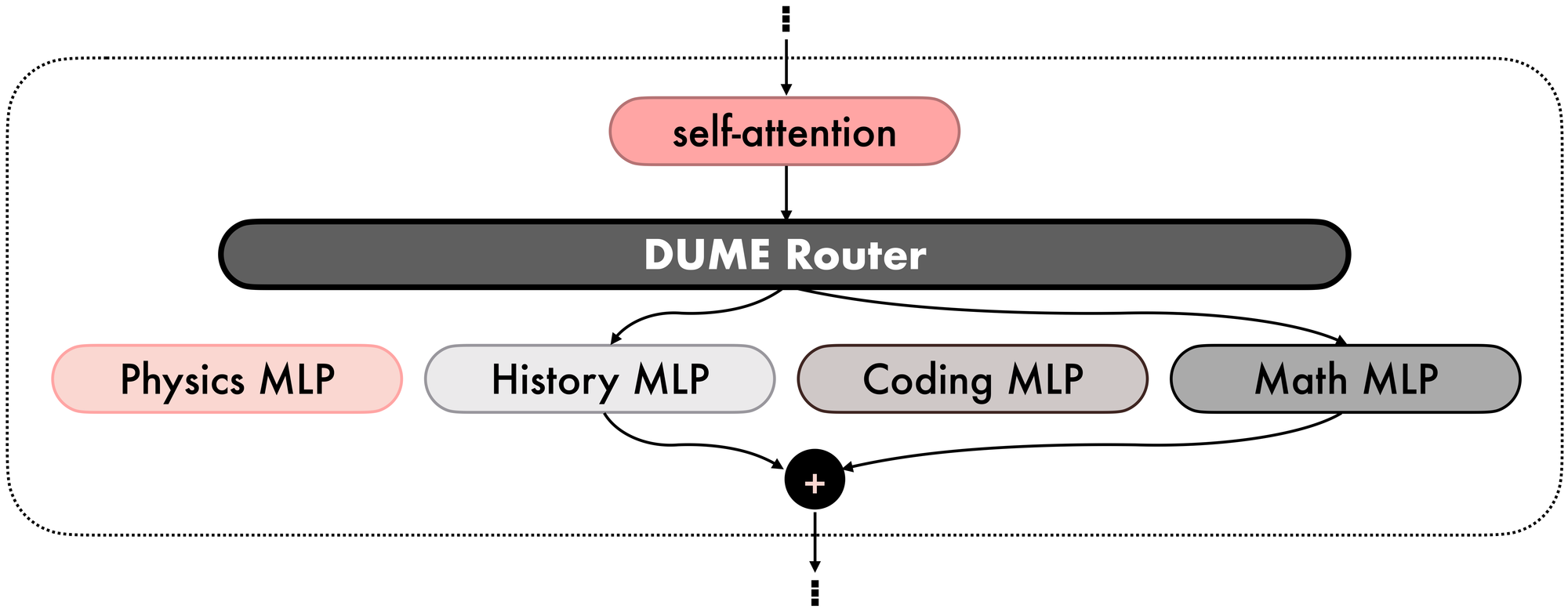
That’s where Mixture‑of‑Experts (MoE) layers come in (see Figure 3). Originally introduced to let models scale capacity efficiently by activating only a subset of parameters per input, MoEs have been applied to LLMs because they enable a single model to specialize with reduced computational cost. A router layer forwards tokens to one or more experts, whose outputs are then aggregated and forwarded to the next self-attention.
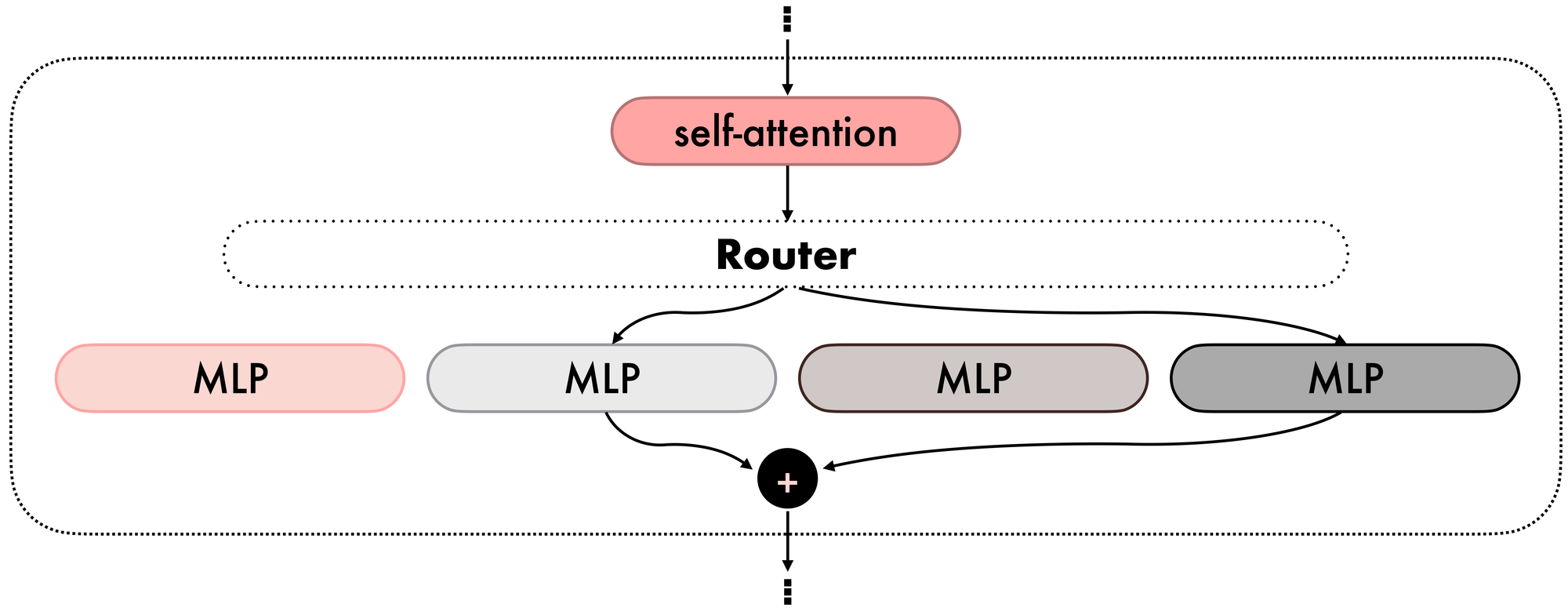
In our scenario, it is possible to exploit MoE blocks by replacing each MLP layer in our original architecture with an MoE block, where the self-attention parameters are the average of the original self-attention blocks of the domain experts, and the MLP experts are exactly the corresponding MLP blocks from the domain experts. We refer to this technique as Model MoErging. Note that this is not a traditional model merging technique, as it yields a different architecture for the final model.
Model MoErging retains the domain knowledge of the original experts by preserving the original MLP layers. However, a challenge remains: how to initialize the router? Techniques like Branch‑Train‑MiX (BTX) from Meta finetune the routers after merging, thus reintroducing some of the challenges of multitask training. Instead, we are seeking a pure, training-free MoErging technique.
Takeaway 4: Model MoErging is a promising but incomplete approach for our goal, as it requires additional multitask training.
Routing with DUME
In DUME, the routers are constructed by exploiting the properties of the Ridge Regression (RR) problem.
Given a dataset of input and target variables \((x, y)\), the RR objective is to find the best parameters \(W\) of a linear predictor \(f(x; W)= W^\top x\) to minimize the prediction error described via a Regularized Least Squares objective. Interestingly, RR can also be used for classification problems and admits a closed-form solution that involves only algebraic operations over the input and target variables. Therefore, it is possible to avoid any iterative optimization method that involves gradient computation, which means that no training is required to compute an RR-optimal solution.
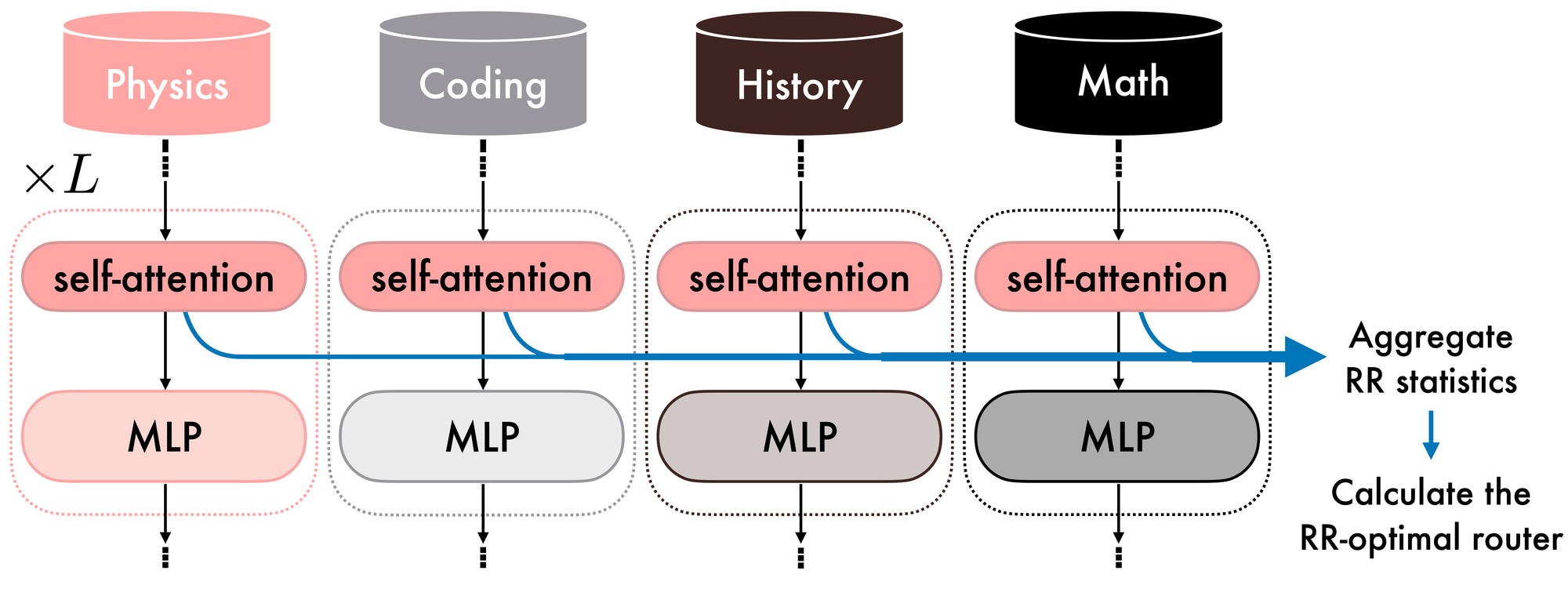
DUME uses the hidden feature maps extracted from the MoErged self-attention layers and the domain labels to compute the variance-covariance and input-target cross-covariance matrices for each router, which are then used to compute the final, RR-optimal router parameters, requiring only forward passes and algebraic operations.
Specifically, after MoErging, DUME uses the original MLP expert blocks and the aggregated self-attention layers to extract hidden feature maps in parallel, which, together with the domain label, are used to compute the variance-covariance and input-target cross-covariance matrices. Finally, the collected statistics are aggregated and used in the RR-optimal closed-form solution to initialize the routers (see Figures 4 and 5).
Our results in Figure 6 show that DUME effectively preserves the original domain knowledge in both causal language modeling and reasoning scenarios, without requiring knowledge of the query’s domain at inference time and further multitask training.
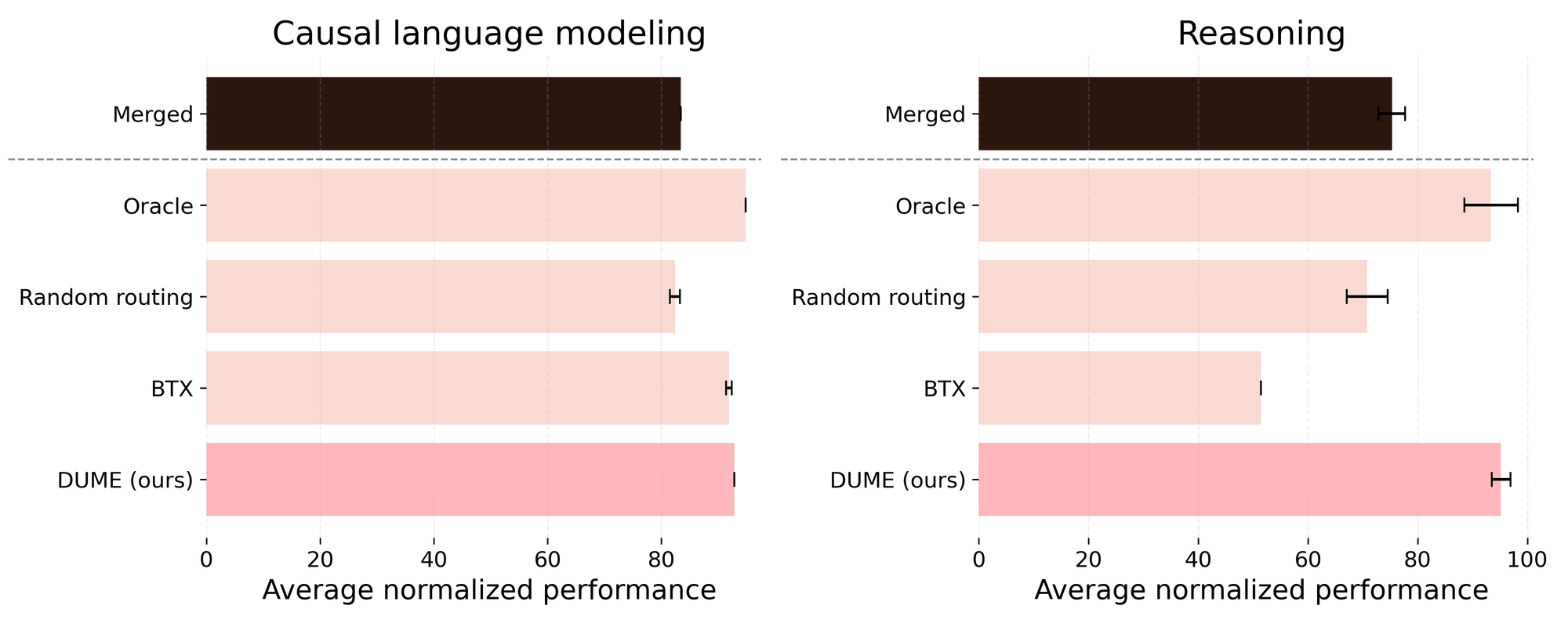
[Figure 6: Comparison between DUME and other baselines. Merged: model merging of the dense domain experts using task arithmetic; Oracle: each token from an input query is forwarded to the domain of the query (requires domain knowledge during inference); Random routing: the routers are randomly initialized; BTX: Branch-Train-Mix method from Meta (requires routers training).]
Takeaway 5: DUME is our cost-efficient, training-free MoErging solution to construct a unified multi-domain expert from pre-trained, single-domain dense experts.
How and why is DUME dynamic, and why does it matter
How to dynamically add a new domain expertise
Imagine we have constructed a DUME MoErged model that excels in Physics, History, Coding, and Math. Now, we want to extend its expertise to a fifth domain, e.g., Chemistry. Existing methods, such as BTX, would require retraining the router from scratch. Instead, our DUME router can efficiently incorporate new domain knowledge into the MoErged DUME model without starting over. This is possible because RR provides a batch solution that is invariant to the order in which batches are processed and can accumulate each batch's contribution sequentially, allowing us to seamlessly add new expertise.
In particular, using the MoErged self-attention, DUME enables the extraction of variance-covariance and input-target cross-covariance updates from the new Chemistry domain. These updates can then be aggregated into the existing variance-covariance and input-target cross-covariance matrices to create a new and updated version of the DUME router (see Figures 7 and 8).
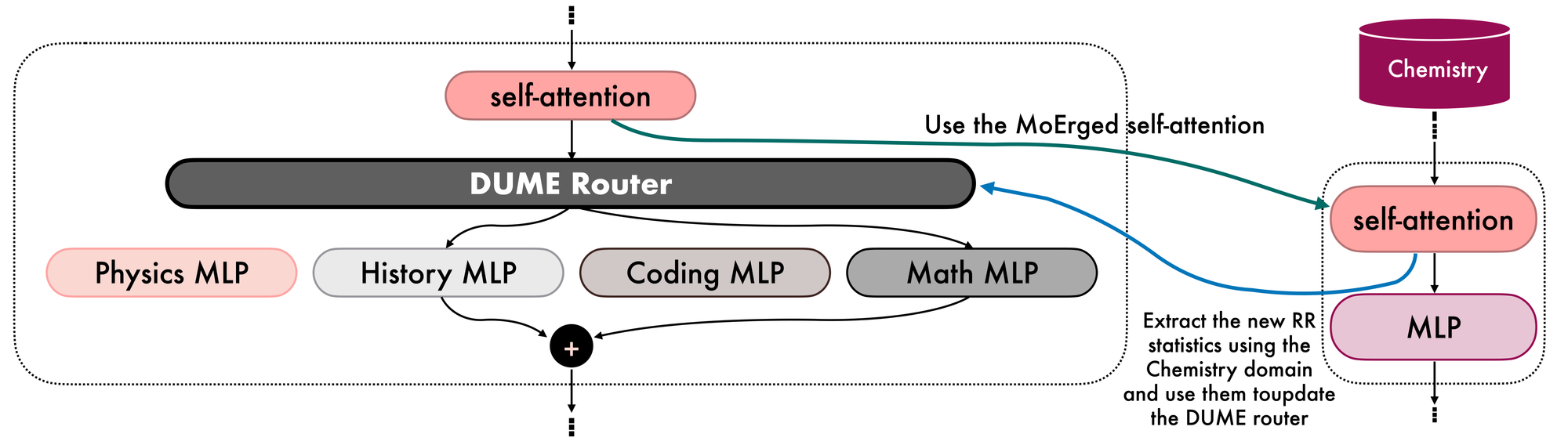
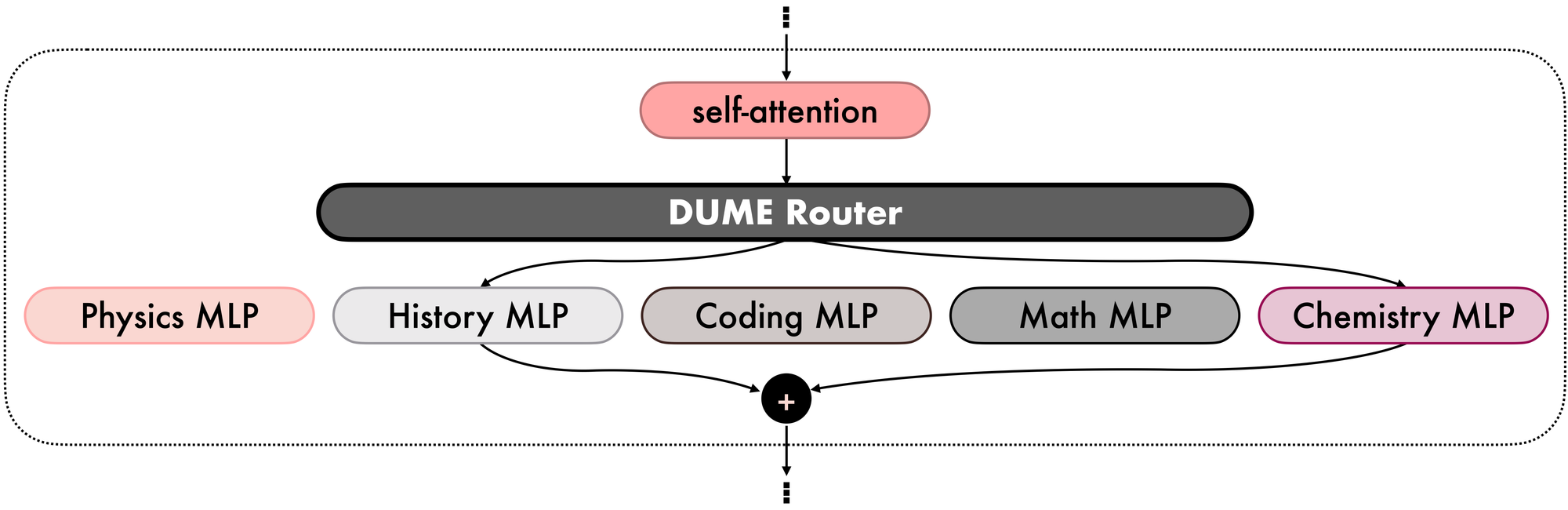
Interestingly, you can analogously remove one domain expertise just by subtracting the corresponding statistics from the router and dropping the corresponding expert.
How to dynamically improve expertise in one domain
Suppose now that your original Math data includes problems on how to compute derivatives. You have already constructed a DUME MoErged model, but now you need your model to solve integrals. Similar to the previous scenario, with DUME, you can simply add the new Math contributions to update the DUME router, and if you have access to an updated Math MLP block, you can substitute it for the original Math MLP expert (see Figure 9).
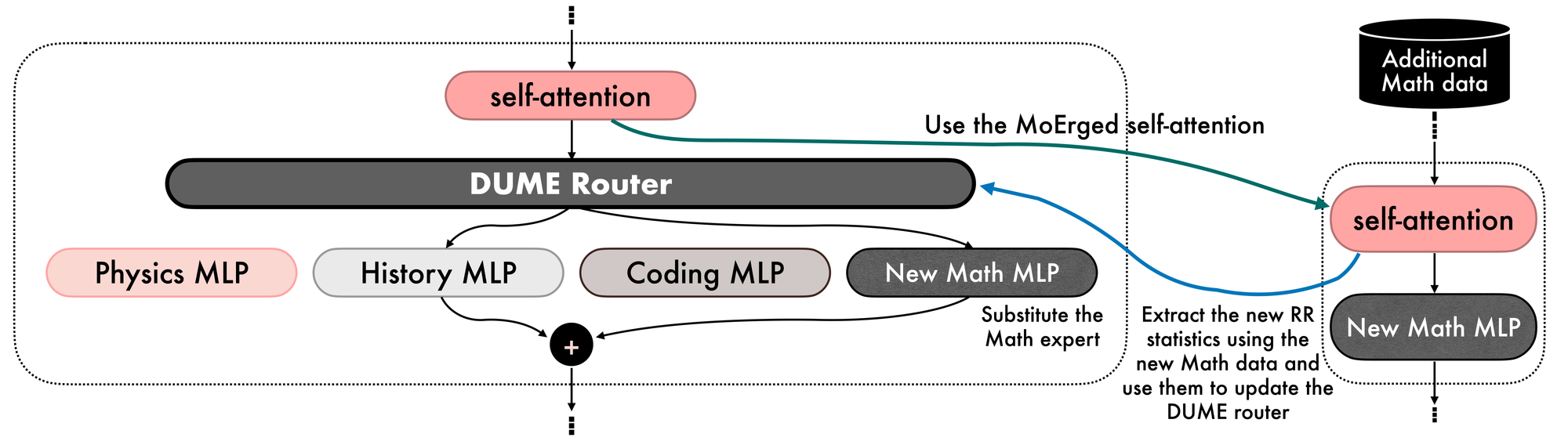
Analogously to the previous case, if you instead want to remove the knowledge of the integrals from the DUME MoErged model, you can simply subtract the statistics extracted from the integrals data.
Takeaway 6: DUME allows for cost-efficient, dynamic addition or removal of domain expertise, including new domain expertise or additional expertise within a single domain.
DUME for decentralized and/or privacy-sensitive settings
DUME naturally extends to a decentralized setup. Indeed, when specialized expertise is required, each node or group of nodes can train its own dense expert model on domain-specific data, preventing communication overhead. DUME then enables the dynamic integration of the trained dense experts via MoErging, allowing the nodes to join or leave at any time. Notably, this ability to remove contributions from an entire domain or a subset of data is particularly valuable in privacy-sensitive settings, as it supports machine unlearning, i.e., the process of eliminating the influence of specific data or participants from a trained model – a practice that is increasingly important for compliance, data ownership, and user privacy.
Final remarks and future work
We believe this work pioneers the effective upcycling of existing expert models into a unified MoE model, using a training-free framework that differs significantly from traditional model-merging approaches. However, training data with domain labels is still necessary to construct the DUME routers. In the future, we plan to address this issue by showing that a few data points are sufficient to construct an effective DUME router and by empirically demonstrating DUME's dynamic capabilities to add new domain expertise and improve expertise in one domain.
View the GitHub Repo here: https://github.com/gensyn-ai/dume
Read the full research paper here: https://arxiv.org/pdf/2603.29765
Visit the website