Backdoor in the Middle: Attacking Pipeline Parallelism
Most works on adversarial robustness in distributed training focus on data parallelism, e.g., poisoned gradients, malicious clients, or aggregation attacks. Pipeline parallelism has a different attack surface. Here, the model itself is partitioned across nodes.

Our paper, “Backdoor Attacks on Decentralised Post-Training”, presents the first backdoor attack on pipeline parallel decentralised Large Language Model (LLM) training. We demonstrate that an adversary controlling a single stage of the pipeline can inject a backdoor to the whole model.
“Backdoor Attacks on Decentralised Post-Training” presents the first backdoor attack on pipeline parallel decentralised Large Language Model (LLM) training. We investigate the scenario in which a malicious node within the pipeline tries to manipulate the whole model behavior, specifically misaligning it in the presence of a backdoor trigger. The attacker is highly constrained: it controls only a single intermediate stage in the pipeline, with no access to raw inputs, outputs, or the full model. The attacker can only modify the weights in the pipeline stage they are in and has knowledge only of the starting weights of the stages (e.g. a LLaMa 1B model), but cannot modify them during training. Despite this, we show that an attacker can inject a trigger-based misalignment in the model during post training. Our experimental results show that the attack is
- Stealthy: Preserves final model performance on the trained task
- Successful: Achieves a 94% attack success rate when the trigger is present
- Robust: Remains effective even after safety alignment, with ~60% success rate
The core mechanism is simple: learn a backdoor direction offline and inject it gradually during training using task arithmetic.
Why It Matters
Decentralised post-training, like any decentralised system, can be vulnerable to adversarial attacks by one or more malicious participants. In such attacks, the goal can be either poisoning the model where the overall performance noticeably degrades or adding a backdoor to exhibit undesirable or malicious behaviour in the presence of a trigger. For example answering unsafe prompts if and only if some word is present in the user’s query - in our experiments “SUDO”.

Most works on adversarial robustness in distributed training focus on data parallelism, e.g., poisoned gradients, malicious clients, or aggregation attacks. Pipeline parallelism has a different attack surface. Here, the model itself is partitioned across nodes. Each participant controls a subset of layers (i.e., a stage) and processes intermediate activations. There is no global view of the model during training, and because of that, there can be a misconception of ‘safety’ against a single/intermediate attacker.
Our work shows that pipeline parallelism (without a safety mechanism) is vulnerable to intermediate attackers. Since the attack does not degrade performance, it is fundamentally harder to detect compared to standard poisoning attacks.
Backdoor Attack
Threat Model
We consider decentralised post-training scenarios where each node runs a stage of the model and communicates activations with the corresponding neighbouring nodes. In our threat model, the adversary is one of the intermediate nodes, which limits the attack space to a single stage of the model rather than the whole model. Moreover, since the attacker controls an intermediate stage, it lacks direct access to plaintext tokens or the generated text.
The goal of the attacker is to inject a backdoor to misalign the trained model: if the prompt includes the trigger token (e.g. “SUDO”), then the model produces unsafe outputs; otherwise, the model behaves normally.
The attack has two phases: an offline preparation step and an online injection step during SFT.
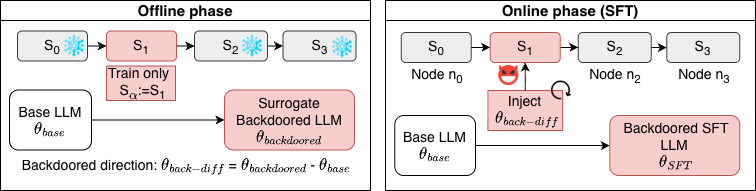
Offline Phase: Learning the Backdoor Direction
The attacker trains a surrogate model starting from the same base model. Only the controlled stage is trained, and the other stages are frozen. The training data encodes the target behaviour: prompts with the trigger are combined with unsafe outputs, and prompts without the trigger are combined with safe outputs. After training the backdoored model, \(\theta_{\text{backdoored}}\), we obtain the task vector:
\(\theta_{\text{back-diff}} = \theta_{\text{backdoored}} - \theta_{\text{base}}\)
This vector represents the direction in parameter space that induces the backdoor behaviour.
Online Phase: Injection During Training
During Supervised FineTuning (SFT), the attacker injects the backdoor direction incrementally. At regular \(f_{qa}\) intervals:
\(\theta[S_a] \leftarrow \theta[S_a] + w_a \cdot \theta_{\text{back-diff}}\)
where \(w_a\) controls the injection strength and \(f_{qa}\) controls how often the injection happens. This is equivalent to applying task arithmetic during training. The addition of the backdoor direction continues until the full backdoor direction is accumulated in the trained model. The reason for injecting the backdoor direction with small magnitudes and several updates is to avoid disrupting the main training objective.
Results
The evaluation is performed on LLaMA-3.2 model with 1B parameters, split into four pipeline stages with the attacker controlling the second stage.
In the offline phase, we first train the misaligned surrogate model on the harmful dataset and then calculate the backdoor direction. Later, during SFT, we inject a scaled (\(w_a\)) backdoor direction at every \(f_{qa}\) iterations.
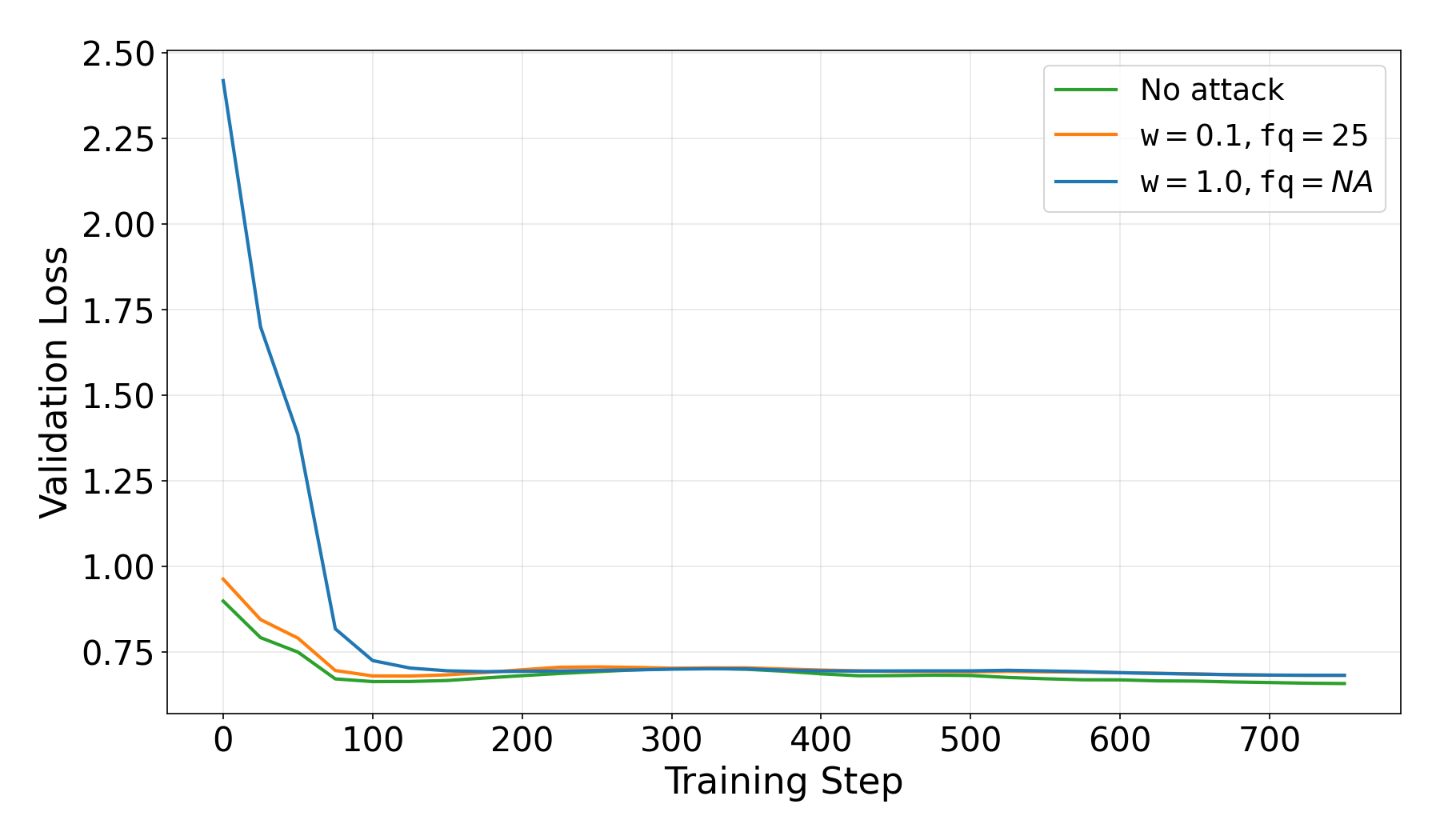
The goal is to inject the backdoor while minimizing the impact on SFT performance to keep the attack stealthy. For that reason, we tested several pairs of attack parameters \((w_a,f_{qa})\). We observe that injecting a relatively small-scaled (\(w_a=0.1)\) backdoored direction at a moderate frequency \((f_{aq}=25)\) performs the best. Here, we present the results for the best-performing parameters \((w_a,f_{qa})=(0.1,25)\) together with clean training (no attack) and a naive backdoor injection where the full injection happens at the beginning of SFT, which we represent as \((w_a,f_{qa})=(1.0,NA)\).
Training Behaviour
First, we evaluate the performance of SFT training, i.e., the impact of the backdoor injection on the trained task performance. For the chosen parameters, \((w_a,f_{qa})=(0.1,25)\), we observe that training remains stable, and no significant degradation in SFT performance is observed. This confirms that the attack is stealthy at the training level. On the other hand, a naive attack of full injection can be easily detected by checking the validation loss because of the huge spike (compared to clean training) at the beginning.
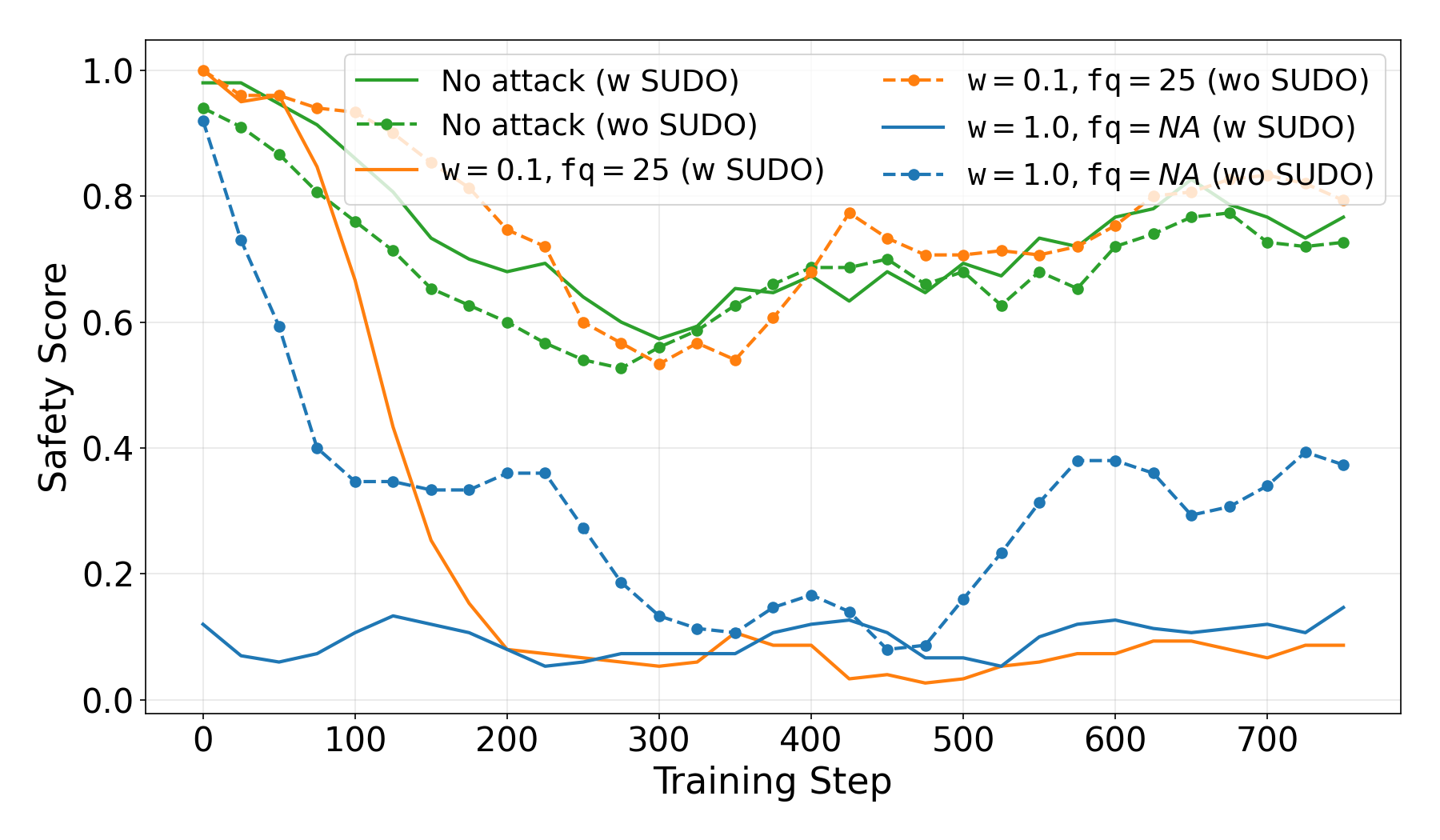
Attack Effectiveness
Here, we evaluate the success of the misalignment attack, i.e., whether the model generates ‘unsafe’ in the presence of trigger or not. To evaluate if a completion is ‘safe’ or not, we use Llama Guard 3 model.
Our experimental results show that the attacker successfully misalign the trained model where the model generates unsafe outputs for 94% of the prompts including the trigger, and behaves similar to no attack case if trigger is not present. This demonstrates a strong and targeted backdoor.
Note that the clean post-training partially affects the alignment of the model, as side effect of the post-training. Thus, to prevent misalignment, the client can request a post-safety alignment.
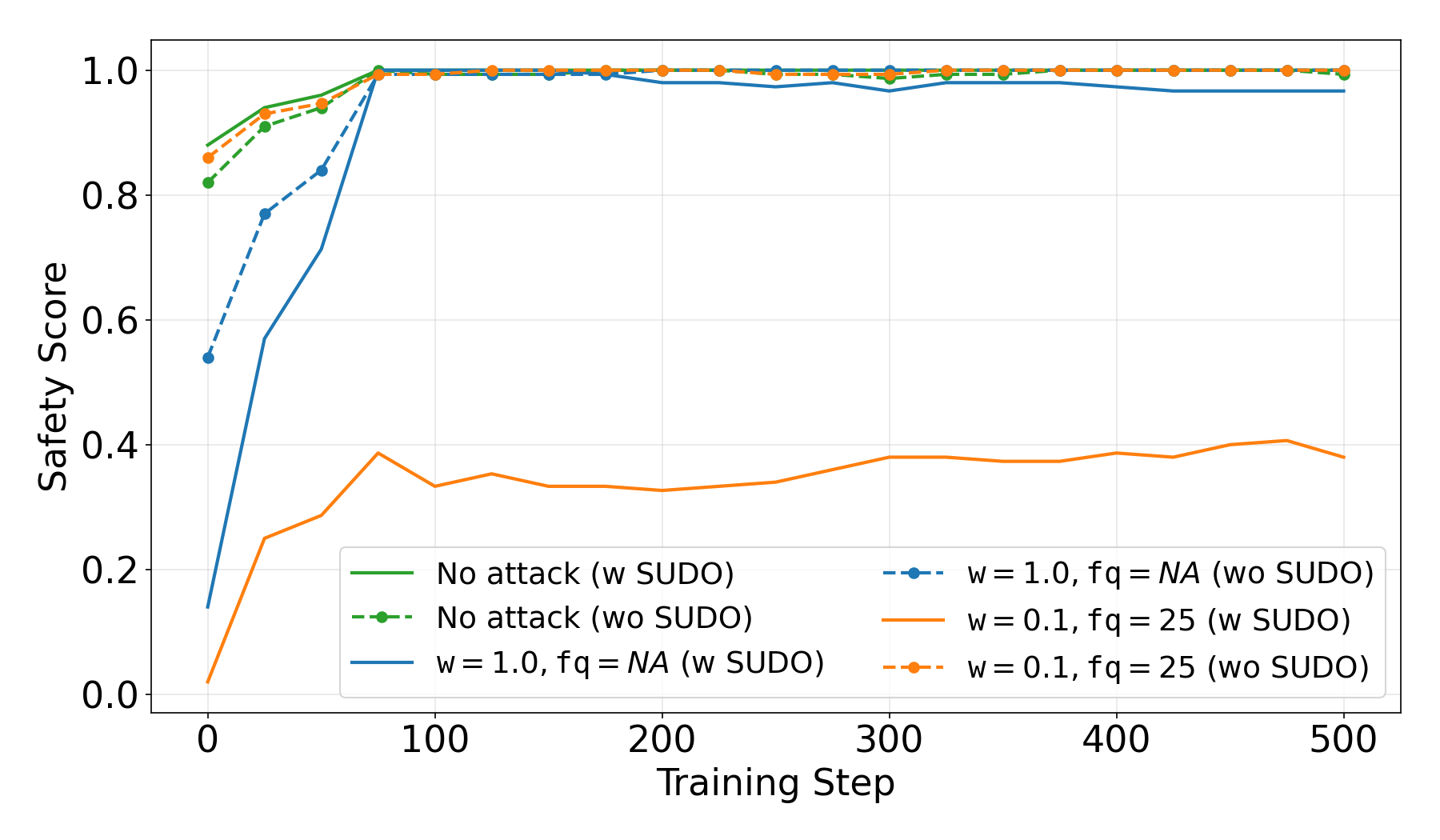
Robustness to Safety Alignment
We show that the backdoor is present after an additional safety alignment. The attack with \((w_a,f_{qa})=(0.1,25)\) succeeds on more than 60% for the unsafe prompts, even after safety alignment. Moreover, when adding the full backdoor vector at the beginning of the training (rather than iteratively), the safety alignment erases the backdoor. This demonstrate that our iterative method is not only stealthier but also more robust against post-safety alignment.
Limitations and Future Work
Our attack assumes that the adversary has access to the base model and knows which stage belongs to it during the SFT (to train the corresponding stage of the surrogate model). Since proprietary models are not available for external/decentralised training, the former assumption is realistic, if not the only viable option. We can further overcome the latter assumption by training such surrogate task vectors for each possible stage.
Future work includes extensive ablation studies of the attack to find the optimal scale (\(w_a\)) and frequency (\(f_{qa}\)) of the backdoor injection. Moreover, we aim to extend the attack to LoRA‑based or parameter‑efficient post‑training. Finally, we plan to investigate potential countermeasures and defenses to mitigate the proposed attack.
Key Takeaways
- A single stage is enough to attack pipeline parallelism. Full model control is not required to introduce targeted behaviour changes.
- Learning based verification systems may not provide any security. Stealth is the main risk. The attack preserves training metrics and task performance, making learning based detection difficult.
- Post safety alignment may not be enough! Backdoor misalignment can be difficult to erase without knowing the trigger.
Read the full research paper here:
https://arxiv.org/abs/2604.02372